🐪工作经验汇总
# 🐪工作经验汇总
“犯过的错误,就不要再犯了罢!加油,优秀的前端er!” —— 沃兹基硕德
# 如何做好一名团队中的新人?
感谢东哥 (opens new window)的经验之谈~作为一名萌新,努力做好团队中的一名新人吧!少说多做,追求快速而合理的成长!
作为新人最重要的事情就一件,就是把手头上的事情做好,这个基本的做不好,其他的都是白扯。 不过做好手头上的事情有一些需要注意的地方/技巧:
- 不懂就问。但是要注意提问之前先翻一翻文档,别问重复的问题,提问的时候讲清楚背景,可以问之前先自己演练一遍
- 维护好私人关系。比如你经常问某人问题,可以私下以奶茶、请吃小饭的形式来做个感谢,因为职场里面没有人有义务给你解答问题
- 可以找个榜样。比如你觉得身边的某人很屌,可以多跟人交流,不过这里需要注意,其实很多人工作了多年依然可能是迷茫的,注意兼听则明
- 手头上事情做好的前提下,可以考虑优化、整理文档手册这种事情,这些事情和主业务是分离的不会耽误业务进度,而且可以体现你的思考
- 多阅读组内的知识库 & 手头项目,学习优秀的部分!
# 常用git命令
常用 Git 命令清单 - 阮一峰的网络日志 (opens new window)
- Workspace:工作区
- Index / Stage:暂存区
- Repository:仓库区(或本地仓库)
- Remote:远程仓库
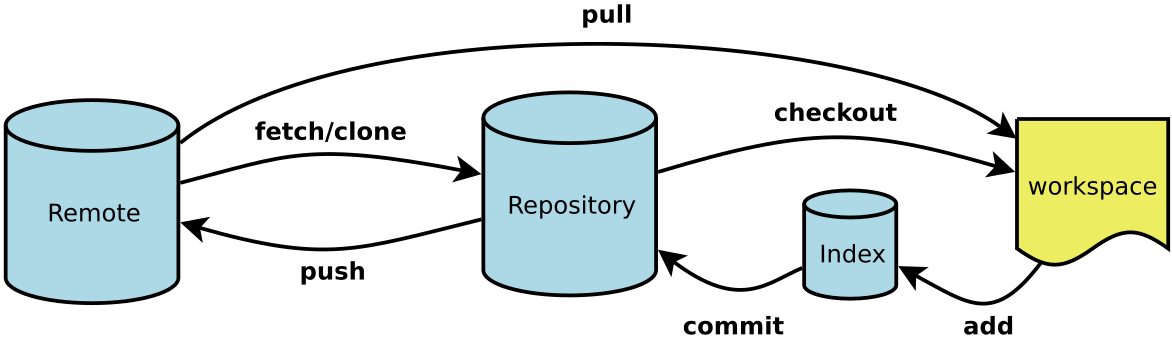
# git的配置
git修改Git的设置文件为.gitconfig,它可以在——
- 用户主目录下(全局配置)
- 也可以在项目目录下(项目配置)。
# 显示当前的Git配置
git config --list
# 编辑Git配置文件
git config -e [--global]
# 设置提交代码时的用户信息
git config [--global] user.name "[name]"
git config [--global] user.email "[email address]"
# 修改、配置、查看用户信息
公司的代码仓库不会允许公司之外的用户向仓库提交代码,所以我们要局部配置用户信息,证明我们是自己人!
注意这里使用
git config user.name "myName"配置用户之后 committer_name为“myName”!!
但是一般公司要求为——
要的是
myName没有引号!所以 根据需要进行用户信息的配置~


git commit --amend --author="author名称 <emial详情>" --no-edit用于更改最近一条的错误committer_name & committer_email
- 查看(局部)配置
- 要查看全局的配置使用
git config --list
- 要查看全局的配置使用
git config user.name
git config user.email
- 局部配置
git config user.name "username"
git config user.email "email"
- 全局配置
git config --global user.name "username"
git config --global user.email "email"
- 局部修改
git config --replace-all user.name "name"
git config --replace-all user.email "@x.com"
# 强制覆盖(撤销)已经提交到远程仓库的无用的commit【慎用!】
先回退到之前的版本
git log 查看想退回去的版本号
git reset --hard 目标版本号
Git 撤销远程仓库的提交(push)和本地仓库的提交(commit) (opens new window)
强制提交提交这个操作之前要问下仓库管理者能不能这样操作,我负责那个项目的前辈给我的指示是——“脏记录没关系,别用
push –force”注意下
git push –force的概念,ta比较暴力——# 强行推送当前分支到远程仓库,即使有冲突 $ git push [remote] --force
# 代码仓库相关规范
# 分支管理 Gitflow工作流概述
一个功能一个分支,写完了一个功能就提pr 提完pr就删除分支~
技术指导:
my-git/git-workflow-tutorial.md at master · xirong/my-git (github.com)(opens new window)

我们假设a与b协作完成一个任务
【1】先创建一个develop分支
精神分裂式开发模式开启!

第一步为master分支配套一个develop分支。简单来做可以本地创建一个空的develop分支 (opens new window),push到服务器上:
git branch develop
git push -u origin develop
以后这个分支将会包含了项目的全部历史,而master分支将只包含了部分历史。其它开发者这时应该克隆中央仓库 (opens new window),建好develop分支的跟踪分支:
git clone ssh://user@host/path/to/repo.git
git checkout -b develop origin/develop
现在每个开发都有了这些历史分支的本地拷贝。
【2】举例:a创建一个功能分支负责写一下CSS,初始化一下项目,
git checkout -b some-feature develop
git status
git add <some-file>
git commit
写完之后推到develop中 然后删除功能分支
个人感觉:功能分支的作用-划分功能时比较清晰且review代码时更加一目了然。想象一下,直接在develop上开发大家就没法每天在自己的分支上进行提交了!这版本该有多混乱!

注意develop上面的版本应该是一个稳定可运行的版本,功能分支推给develop分支的版本应该较完善才对!
git pull origin develop
git checkout develop
git merge some-feature
git push
git branch -d some-feature
【3】举例:b也基于develop创建一个功能分支,进行项目核心功能的开发~与【2】的流程同理
疑问:那再来一拨人开发不太相干的内容是否需要再搞一个develop2出来呢?还是说再搞一个功能分支出来?
【4】进行发布 涉及到release层
等两边分别开发得差不多了就整一个release
git checkout -b release-0.1 develop
这个分支是清理发布、执行所有测试、更新文档和其它为下个发布做准备操作的地方,像是一个专门用于改善发布的功能分支。
【5】完成发布 将修改合并到main分支
git checkout main
git merge release-0.1
git push
git checkout develop
git merge release-0.1
git push
git branch -d release-0.1
【6】特殊情况——比如:修改之前版本的问题
git checkout -b issue-#001 main
# Fix the bug
git checkout main
git merge issue-#001
git push
就像发布分支,维护分支中新加这些重要修改需要包含到develop分支中,所以要再在develop执行一个合并操作。然后就可以安全地删除这个分支 (opens new window)了:
git checkout develop
git merge issue-#001
git push
git branch -d issue-#001
# commit命名规范
'feat', // 新功能 feature
'fix'/'', // 一个错误修复
'refactor', // 重构(既不增加新功能,也不是修复bug)
'docs', // 仅文档更改
'test', // 添加缺失的测试或更正现有的测试
'chore', // 构建过程/辅助工具等的修改
'style', // 不影响代码含义的更改(空白,格式,缺少分号等,即为 格式调整)
'perf', // 改进性能的代码更改
'revert', // 回滚到某个版本
'ci', // CI配置/脚本的调整
'test', // 测试调整(增加测试用例等)
// eg: 'feat: 添加了图表功能'
# 推代码之前要先拉取(在同一个分支上开发/子分支拉父分支)
git push时出现的Merge branch ‘xxx‘ into ‘xxx‘ (opens new window)
git解决merge branch_球球之家-CSDN博客 (opens new window)——解决方案——在push失败的时候,先pull,然后force rebase再push即可解决
如果没养成这种习惯,会导致git log中出现“Merge branch ”xxx” into “xxx” 这一条 不够规范!

# 合并代码的四种方式-merge squash rebase
组内知识手册
若评审通过后,根据合并策略的设置,确定是否需要自动合并到目标分支。
- 若合并策略勾选了允许评审通过后自动合并代码,则代码将会自动合入到目标分支;
- 若未勾选,则需要目标分支有权限的成员,根据需求,选择相应的合并方式进行手动合并; 我们提供四种合并方式:
四种代码合并方式的定义
Merge:这种方式会优先尝试fast-forward(快进)方式merge,若行不通,再尝试non-fast forward方式。默认方式
Merge with non fast-forward:采用non-fast forward方式merge,总是会在目标分支头部生成一个合并点。
Squash and merge:将源分支上所有要合并的commits先汇合成一个commit,然后提交到目标分支头部。
Rebase and merge:Rebase是一种变基操作,本质是将source branch的commits一个一个有序的cherry pick到目标分支头部,保留每个commit的内容但变更sha1。使目标分支的版本树看起来是一条线,简洁易读。
手动合并选择页面如下图:

四种合并方式的定义与图解
# 1. Merge
这种方式会优先尝试fast-forward(快进)方式merge,若行不通,再尝试non-fast forward方式。这个方式是默认方式。
# 示例一:fast-forward方式
如下图所示,bugfix分支从master分支branch out(切出来)。

合并bugfix分支到master分支时,master分支的状态没有被更新过。 此时Merge会优先采用fast-forward(快进)方式,将master分支的head移动到bugfix分支的最新提交。merge后的版本树如下图:

# 示例二:non-fast forward方式
同样的,bugfix分支从master分支branch out,但此后master分支上有新的提交。

合并bugfix分支到master分支时,Merge会采用**"non-fast forward"**方式,在目标分支头部生成一个新的merge point E。merge结果如下图:

# 2. Merge with non-fast forward
采用non-fast forward方式merge,总是会在目标分支头部生成一个merge point(合并点)。
# 示例:
如下图,bugfix分支从master分支branch out,此后master分支没有再被更新过。

采用non-fast forward方式合并bugfix分支到master分支时,会在目标分支master头部产生一个merge point C。如下图示意:

# 3. Squash and merge
将源分支上所有要合并的commits先汇合成一个commit,然后提交到目标分支头部。
# 示例:
采用squash方式合并bugfix分支到master分支时,bugfix分支的commitX和commitY会先被汇合成一个commit,然后被提交到master分支头部。如下图示:

# 4. Rebase and merge
好文推荐,点出了很多应用场景git rebase vs git merge详解 - 世有因果知因求果 - 博客园 (cnblogs.com) (opens new window)
Rebase是一种变基操作,本质是将source branch的commits一个一个有序的cherry pick到目标分支头部,保留每个commit的内容。使目标分支的版本树看起来是一条线,简洁易读。
cherry-pick即“摘樱桃”,使用该命令可以将任意的commit通过其commit号将其合并到你想要的分支上
# 示例:
采用rebase方式合并bugfix分支到master分支时,bugfix分支的commitX和commitY会被有序的添加到master分支的头部。如图所示,master分支的历史记录成一条直线。

# SSH在git中的意义
SSH是一种协议标准,其目的是实现安全远程登录以及其它安全网络服务.
SSH(Secure Shell)仅仅是一个协议标准 ,其具体的实现有很多,既有开源实现的OpenSSH,也有商业实现方案.使用范围最广泛的当然是开源实现OpenSSH.
如何实现数据的安全呢?首先想到的实现方案肯定是对数据进行加密.加密的方式主要有两种:
- 对称加密(也称为秘钥加密)
- 非对称加密(也称公钥加密)
非对称加密

1.远程Server收到Client端用户TopGun的登录请求,Server把自己的公钥发给用户.
2.Client使用这个公钥,将密码进行加密.
3.Client将加密的密码发送给Server端.
4.远程Server用自己的私钥,解密登录密码,然后验证其合法性.
5.若验证结果,给Client相应的响应.
可能出现的安全问题,中间人攻击——
Client端不能保证接受到的公钥就是目标Server端的,如果一个攻击者中途拦截Client的登录请求,向其发送自己的公钥,Client端用攻击者的公钥进行数据加密.攻击者接收到加密信息后再用自己的私钥进行解密,不就窃取了Client的登录信息了吗?这就是所谓的中间人攻击

SSH的作用 在非对称加密中 (帮助客户端)对服务端的公钥进行认证
- 在https中可以通过CA来进行公证,可是SSH的publish key和private key都是自己生成的,没法公证.只能通过Client端自己对公钥进行确认
SSH基于公钥进行认证的方式——


作者:shuaiutopia 链接:https://www.jianshu.com/p/cab7e436a7aa 来源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
# 效率工具
mac环境的 oh my zsh
# autojump
记忆化地jump到你曾经cd到过的地方,尤其适合GUI与命令行灵巧结合的mac
# 项目性能优化
# 项目难点
# 工作经验汇总
# 项目中readme的规范
1.项目简介
2.项目地址
线上:prod(正式)、stagein(预发)
线下:test(公共测试环境)、dev(研发自用环境)
prod
stage
test
develop
3.项目结构
4.开发步骤
- 开发工具
- 安装依赖
- 启动服务
5.相关文档
# 多从产品、后端的角度去思考问题!
灵活一些 可以减少一些沟通成本!
# 不要使用意义不明的变量,使用映射进行代替
// bad
if (str.includes('1')) {
} else if (str.includes('2')) {}
// good
const xxMap = {
tip1: '1',
tip2: '2',
}
if (str.includes(xxMap.tip1)) {
} else if (str.includes(xxMap.tip2)) {}
- 这样写后期如果想修改具体的字段对应的映射(比如 tip1传入的参数改为0 tip2改为1) 会非常方便,写逻辑的时候也会直观很多!
# 组件封装注意事项
样式问题
- 组件只在乎自己内部的样式 不要设置组件整体的margin padding 这样普适性太差了!
减少与业务强相关的变量、方法 通过业务组件的传值解决这部分需求
用户自己传入style 更加灵活、扩展能力更强
封装好的组件中的方法里尽量不要加上业务变量
- 以功能为目的
要时刻考虑可以把哪些内容封装成组件
- 四个tab页-每一个都对应一个
treeSelect要求treeSelect是独立的——可以把ta封装成MyTree组件
- 四个tab页-每一个都对应一个
# 高内聚,低耦合
- 逻辑高内聚的原因——之后好定位错误改bug,代码优雅
- 比如在
getData方法中进行了列表的请求,如果其他方法中想发起同样的请求,调用getData并向其中传值即可~
# 代码规范
这个交给
Eslint就好了,组里前辈都把规范配置好了,用就完事了~
造轮子的问题 这个回头考虑~

# 业务组件的使用
业务组件一般在View文件夹中
封装好的普适性组件一般在Components文件夹中
在封装普适性组件时要全面考虑,这样在写业务组件时才会比较舒服~
# debug大型项目技巧
前置知识:ES6 React基本思想、一些基础钩子的用法
- 找到问题所在页面,根据路由path
/xx/xx找到对应的组件所在位置 - 拿到一个组件先一一对应页面与代码,并进行理解,定位问题的位置
- 找到有问题的组件, 要明白对应属性的概念并合理应用 传入值进去——
- 现成的组件库 打开官网 通过demo/API 理解用法 定位问题/添加需求
- 组内封装好的组件 理解其暴露出来的属性 并且顺着这些属性理解组件渲染出来的效果 并定位问题所在
- 最后 多干掉几个bug就有感觉了 慢慢来吧!
# 用 useRef 钩子代替 useState 钩子做组件内的状态管理
待了解
useRef的更多用法…
useRef (opens new window)可达成与 useState类似的效果
在无法使用useState钩子时 考虑使用useRef 钩子来进行代替,二者区别——
setState函数用于更新 state。它接收一个新的 state 值并将组件的一次重新渲染加入队列。- 变更
.current属性不会引发组件重新渲染。
# 实现新需求的同时,尽可能地减少冗余代码并高度集成功能:
这里是我 简历中JDT实习期间第一个项目的负责内容汇总
- 重写复用性不够好的公共组件;
- 将通用数据以硬编码的方式提升到配置文件中,保证不同业务组件中不会出现冗余的字段;
- 通过改写对用户信息的存储、获取方式(使用
mobx存储状态),减少了业务组件中发送对应请求的次数,减轻了页面加载渲染负担;
# 项目目录结构
后台管理项目的结构——稍微有些老旧的一个项目结构 仅供参考
遇到一个项目 可以尝试着按照这个方式把每一部分过一下 了解下项目的内容~
- build # webpack 配置文件 里面会区分不同环境
- config # 环境变量 比如 不同环境的请求前缀不一样
- docker # 部署镜像用的,切换分支的时候,如果需要部署不同版本的,修改sh,三个环境
- public
- favicon.ico
- index.html # 入口html
- static # 静态文件
- src
- components # 项目通用型组件
- config # 定义常量
- fileDemo # demo 文件用于调试的
- font # 字体及图表
- hooks # 自定义react hook, useState, useRef
- image # 静态图片比如icon,png,jpg
- modules # 一个个独立的模块。目的,js模块化,想把一个模块暴露出去给其他项目用
- router # 路由: 路由配置文件(?路由拆成一个个子模块)权限路由的逻辑
- service # 接口配置 应该按照服务划分,不应该按照菜单划分
- store # 状态管理
- theme # 主题样式
- util # 工具函数
- views # 视图层
- wiki # 放设计文档
- index.js #入口js 注入了store
- package.json
- .env.[mode] # 环境变量
- lerna.json
- README.MD
# 修bug不要靠猜!要有想法一些!
修一个异步请求抛出的错误时 前辈无奈地这么教导我
【1】正确追溯到有问题的地方
【2】了解对应内容的逻辑
【3】找出问题,进行修改
而不是“把这个删了试试?在这里加点东西试试?” 不对!!
多打断点
# 添加自定义环境变量 (opens new window)
添加自定义环境变量 · Create React App 中文文档 (opens new window)

# 环境变量都有啥
在生产、开发、测试环境中希望有不同执行的操作
例如 不同的登陆地址 不同的跳转路径
# 灵活使用硬编码
22/3/4
写业务的时候发现有三个组件中存在完全一样的场景,重复写了三遍
statusMap这就很冗余 之后如果想改map中的一个字段 就得改三遍 很麻烦!放到config里统一管理最好!
22/3/18
场景:一个段落文字对应的组件-进行了笨拙的分情况讨论(共三种情况,只有一个字段略有不同) —— 通过硬编码建立映射
“硬编码的思想:一种逻辑的抽离,代码地健壮、可扩展性”
“一部分代码写好了,之后产品加新需求/后端新增字段的时候,能动的代码越少,那么这段代码就更好”
同时也要注意不要为了封装而封装,这段封装要有意义(重复代码较多的时候就要思考可以进行一下硬编码了!)

# 一些相似的页面直接复制粘贴就可以,需要额外改改名字、router等配置内容
- 常用在迭代老项目中,新项目需要从头开始码啦~
- 先整个粘贴过来 然后commit一版 之后在此基础上进行细节的一些修改,就可以对比改了哪些部分,改的对不对,更好review代码!
# 取名不要掺杂太多业务的内容 这样比较好复用~
比如在一个注册任务的组件功能是这样的——
点击按钮触发回调,生成一个弹窗
如果你取名叫 createTask,就比较有局限性,后期如果在其他组件中服用这个方法 还得疯狂改名字(因为这种方法一般也会带一些其他变量 啥 taskDat变量啊啥的)
起名为 createModal,也就是创建弹窗 就可以在所有存在弹窗的场景都应用这个方法~
非常方便!
# 反复思考如何使用更少的状态变量来实现业务
删去冗余的存储变量可以降低空间复杂度
减少变量也可以让后续新添需求更加轻松,适当添加一些注释,让代码更加容易理解~
# 批量修改一些代码时,先将代码加入缓存区,再进行修改 利用vscode的源代码管理工具就可以方便看出更改的内容
git add .
# 工作踩坑经验
# 画页面的时候把样式还原得好一些!职业一些!
mentor发现我切好的页面和设计稿差距有点大的时候微微皱起了眉头😢
# 退出git log命令,退出
啊好蠢的问题
输入q
# Please enter a commit message to explain why this merge is necessary.
请输入提交消息来解释为什么这种合并是必要的
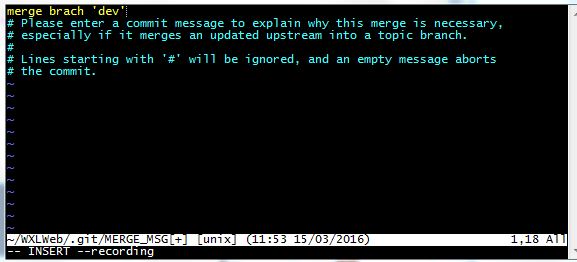
git 在pull或者合并分支的时候有时会遇到这个界面。可以不管(直接下面3,4步),如果要输入解释的话就需要:
1.按键盘字母 i 进入insert模式
2.修改最上面那行黄色合并信息,可以不修改
3.按键盘左上角"Esc"
4.输入":wq",注意是冒号+wq,按回车键即可
八年前的一个老问题 hh
# 防止平台崩溃用不了——做容错处理
年前平台因为这个问题崩溃了一次,因为一个请求500 导致整个系统用不了,裂开😶🌫️
22/3/21又碰到了这样的问题,忘记做容错处理了!后端返回数据变化之后页面直接白屏了
如果后端返回的数据obj为null 则前端的代码中不要出现obj.xxx这种用法
会导致平台整个用不了
建议使用
obj && obj.xxx ——逻辑与运算 —— 来做一个防范
保证不会因为后端没有返回数据导致前端页面白屏!
let list = api.getList(); // 防范返回值为null!
// bad
list.map((item) => {
return item
})
// good
list && list.map((item) => {
return item
})

# 跨域问题
暂时还没在工作中踩过坑 前辈都帮着把路铺好了,看看未来什么时候能遇到“铺路”的场景 哈哈
- 由来
- 什么是同源策略及限制,什么组成了源,跨域会导致哪些不能无法操作。
- 前后端通信的几种方式,跨域通信的几种方式
- 解决方法
- jsonp:实现原理,有什么局限; 只能发 get 请求
- cors:实现方式,配置跨域头,这些跨域头的含义,跨域携带 cookie 的问题
- 转为同域: 做代理
# 提交代码push规范
- 提交代码之前要在vs code中自我review一下!
- 另外注意自己push的时候所在的分支!

刚开始工作的时候稀里糊涂地随意提交搞出来脏提交分支的感觉非常蓝受!
(注意:提出来脏分支问题不是很大,没必要退回之前版本然后用git push --force来强推,这个更不规范!)
# setInterval中不要使用useState中的方法修改变量
应该是闭包引发的问题
setInterval和useState-在间隔内使用更新状态的条件语句 (opens new window)
传递到
setInterval闭包的回调只访问第一次呈现中的时间变量,而在随后的呈现中它无权访问新的时间值,因为第二次没有调用useffect()
下面的setData方法是异步的 , 如果使用在setInterval中会导致无法正常更新data的数据
const [data, setData] = useState({});
const getList = ()
因为没有在setInterval中更新data的数据 导致我当时做的一个 定时发送getList请求的需求出现问题——切到第二页之后隔一段时间发送的请求附带的参数是第一页的
解决问题:使用了钩子
useRef(opens new window)以下代码去除了与
useRef以及定时刷新业务无关的大部分代码 无敏感数据~注意观察下面各个方法中
getList的使用方法~
import React, { useRef } from 'react';
import { withRouter } from 'react-router-dom';
const DEFAULT_QUERY = { page: 1, page_size: 10 };
const xxxTask = () => {
// 👇之前使用的 const [query, setQuery] = useState(DEFAULT_QUERY) 改用useRef钩子
const queryRef = useRef(DEFAULT_QUERY);
const getList = async (params = DEFAULT_QUERY) => {
try {
const newQuery = {
...queryRef.current,
...params
};
queryRef.current = newQuery;
// 传入基础参数(各种id)与新参数(newQuery) 调用对应接口
const res = await getTaskLists({
project_id: urlFormat(location.search).id, user_id: userId || userid,
...newQuery
});
// 获得要渲染的列表
setListData(res.tasks_list);
} catch (error) {
message.error(error.message);
}
};
// 换页的回调函数
const changePagination = (current, pageSize) => {
getList({ page: current, page_size: pageSize });
};
useEffect(() => {
setPrejectId(urlFormat(location.search).id);
getList();
const reloadDataTimer = setInterval(() => {
getList({}); // 不能覆盖原来的query参数
}, 5000)
// 销毁组件时清除掉计时器
return () => {
clearInterval(reloadDataTimer);
}
}, []);
// 渲染的任务列表-一部分
const columns = [
{
title: '任务名称',
dataIndex: 'task_name',
key: 'task_name',
},
{
title: '创建时间',
dataIndex: 'created_time',
key: 'created_time',
},
];
// 删除一个任务 使用async await发送异步请求
const delTask = async (taskName) => {
try {
await deleteTask({ project_id: urlFormat(location.search).id, user_id: userId, task_name: taskName });
message.success('删除成功');
getList(); // 重置列表,回到了第一页
} catch (error) {
message.error(error.message);
}
};
return (<div className={styles.predictiontask}>
<div className={styles.predictiontask_body}>
<div className={styles.content}>
<div className={styles.add_task}>
<Button type="primary" size="middle" icon={<PlusOutlined />} onClick={() => history.push(`/workspace/model-experiment/prediction_task/add_task?id=${prejectId}`)}>新建任务</Button>
</div>
<Table
columns={columns}
pagination={{
total, showTotal: () => `共${total}条`, showQuickJumper: true, onChange: changePagination,
pageSize: queryRef.current.page_size
}}
loading={loading}
dataSource={listData}
rowClassName={setRowClassName}
rowKey="task_name"
/>
</div>
</div>
</div>
);
};
// 使用withRouter使location参数可以拿到浏览器地址栏的参数~(不用withRouter的话 直接从上层传下来location 也可以用~)
export default withRouter(PredictionTask);
# setList({ …newList })来进行更新 而不是使用setList(newList)
const [list, setList] = useState({ a: 1, b: 2 });
list.a = 2;
最基础的点上踩坑,没谁了。。
使用同一个对象(newList)来更新的话setList表示他并不认账——
setList(list); // 这样是不能成功更新list的!这个list(在堆中的)地址没有变!
使用全新的对象进行更新才对!——
setList({ ...list }); // 使用新对象来更新
# (工作前期)开发新功能的时候不要没想好就开始写(要先问好前辈这么写对不对)
有可能你的想法是很复杂且不正确的!
碰到一个点:(组件关系 任务->模型)
要求:hover在任务的一个字段上的时候要显示数据,数据从任务对应的模型中拿到。
我当时就想着给模型组件传个方法过去 然后让子组件调用这个回调方法,这样任务中就可以拿到数据了
这样缺点很多——
- 需要频繁调用子组件中的方法
- 难写!!
实际上直接让后端把具体的数据给返回下就好了…
# 封装组件时最好不要使用状态管理库中的方法 最好直接调service中的接口
调状态管理库中的方法有可能会影响状态管理库中存储的内容!