👨💻解题技巧与必会算法
# 👨💻解题技巧与必会算法
# 01 双指针
- 同向而行快慢指针(常用于链表)
- 反向而行双指针(对撞指针,常用于数组)
# 【1】链表中的双指针
【medium】19. 删除链表的倒数第 N 个结点 (opens new window)
【easy】206. 反转链表 (opens new window)
【medium】92.反转链表 II (opens new window)
# 【2】有序数组中的双指针-求和、比大小
前提为:数组有序——以便双指针帮助我们缩小定位的范围。
【easy】88. 合并两个有序数组 (opens new window)
【medium】15. 三数之和 (opens new window)
# 【3】快慢指针
巧妙利用快慢指针解决移动某些元素(通过交换)、删除某些元素 等问题
# 283. 移动零 (opens new window)
function moveZeroes(nums: number[]): void {
let slow = 0, fast = 0;
while (fast < nums.length) {
if (nums[fast] !== 0) {
[nums[slow], nums[fast]] = [nums[fast], nums[slow]];
slow++;
}
fast++;
}
};
# 02 哈希表
这个真的是超级常用的技巧~ 熟练使用哈希表可以解决许多高频问题!
在《必会数据结构》-数组&字符串 部分 我多次使用哈希表进行解题
# 借助Map的哈希表求解
这种比较常规,正如上面提到的——必会数据结构-数组&字符串 中 经常使用
# 不借助Map的哈希表求解
有些哈希表题目如果使用了Map是没有必要的 甚至会导致解不出来题目(因为Map数据结构是一个映射的关系),记录一下这些题目!
# 1189. “气球” 的最大数量 (opens new window)
2/13的每日一题 非常棒的一题!
哈希表 字符串- 使用数组存储数频
- 在求解有限、规律的元素时 不需要使用Map!
var maxNumberOfBalloons = function(text) {
let textArr = new Array(5).fill(0);
for (let i = 0; i < text.length; i++) {
if (text[i] === 'b') {
textArr[0]++;
} else if (text[i] === 'a') {
textArr[1]++;
} else if (text[i] === 'l') {
textArr[2]++;
} else if (text[i] === 'o') {
textArr[3]++;
} else if (text[i] === 'n') {
textArr[4]++;
}
}
textArr[2] = Math.floor(textArr[2] / 2);
textArr[3] = Math.floor(textArr[3] / 2);
return _.min(textArr);
// return Math.min.apply(null, textArr);
};
# 03 递归
- 递归的基本原理 掌握递归调用栈思想 由浅入深研究递归🎉 (opens new window)
- 树的前中后序遍历
- 数组、链表等题目中的递归骚操作
# 04 DFS BFS
# 【1】DFS 深度优先搜索
之前写的专题记录深度优先搜索 leetcode104 101 112 543 129 五道题小练一下深度优先遍历搜索算法 java刷题笔记 (opens new window)
一句话理解DFS:走迷宫,不撞南墙不回头,撞了南墙回到上一个节点再次去撞南墙(取决于有几个岔路口),撞遍当前节点的南墙再往回退一个节点(换个岔路口),以此类推…
本质为栈结构
- 搜索过程中的前进、后退操作与栈结构的入栈、出栈过程很相似!
# 二叉树中的DFS
还是根据上例来说,我们使用递归编程解决这个问题——递归式就是我们选择道路的过程,而递归边界就是“南墙”
在二叉树中
- 节点就好比是迷宫里的坐标
- 图中的每个节点在作为父节点时无疑是岔路口
- 空节点就是“南墙”。
比如二叉树的前序遍历就是一个策略明显(先撞左侧的南墙,撞穿勒左侧再去撞右侧,然后再回到前一个节点…)的DFS的过程——空节点就是这个问题里的“南墙”,
也可以说 先序遍历是DFS思想的递归实现,后面我们接触的很多题都可以用DFS思想来递归实现!(不撞南墙不回头~)
来看看代码——
function preorder(root){
if(root === null){
return;// 边界条件——“南墙”
}
console.log(root);
preorder(root.left);
preorder(root.right);
}
# 为什么说DFS的本质是栈?
我的理解:DFS的实现与栈的原理类似(一般都用递归来快速模拟深度优先搜索的过程,而递归的原理就是“函数调用栈”)
修言大大的理解 (opens new window)(本知识库中好多思想都是从修言大大的这本掘金小册学来的!真的很受用!)
- 首先,函数调用的底层,仍然是由栈来实现的。JS 会维护一个叫“函数调用栈”的东西(类似的思想我写过一篇文章 掌握递归调用栈思想 由浅入深研究递归🎉 (opens new window) 就是说这个递归调用栈的~),
preorder每调用一次自己,相关调用的上下文就会被push进函数调用栈中;待函数执行完毕后,对应的上下文又会从调用栈中被pop出来。因此,即便二叉树的递归调用过程中,并没有出现栈这种数据结构,也依然改变不了递归的本质是栈的事实。- 其次,DFS 作为一种思想,它和树的递归遍历一脉相承、却并不能完全地画上等号——DFS 的解题场景其实有很多,其中有一类会要求我们记录每一层递归式里路径的状态,此时就会强依赖栈结构(这一点会在下一节的真题实战中体现得淋漓尽致)。
# 【2】BFS广度优先搜索
之前写的专题记录
广度优先搜索 刷熟一个模板(层序遍历打印二叉树)秒杀一堆问题leetcode102 111 116 617 java刷题笔记 (opens new window)
DFS的实现与栈的原理类似
而BFS的实现与队列密不可分,做一道贼经典的题就知道了
# 102. 二叉树的层序遍历 (opens new window)
我们要做的是对这个二叉树进行层序遍历。
层序遍历的概念很好理解:按照层次的顺序,从上到下,从左到右地遍历一个二叉树,如图所示(红色数字即为遍历的序号):
欸嘿!这不就是我们的BFS广度优先搜索麽!
- 效率有点低 但是好想的方法~每一层都有个辅助数组temp
var levelOrder = function(root) {
let res = [];
if(root === null){
return res;
}
const queue = [];// 用队列辅助进行二叉树的广度搜索
queue.push(root);
while(queue.length){
console.log(queue);
let temp = [];// 存这一层的节点
let currentL = queue.length;// 存当前这一层有几个节点~
for(let i = 0; i < currentL; i++){
// 将这一层的所有节点广度搜索一遍,并顺带着探索一下每个节点的下一层有没有节点,如果有则加入到队列中
let node = queue.shift();
temp.push(node.val);// 将每一次for循环遍历得到的节点值加入临时数组temp中
if(node.left !== null) queue.push(node.left);
if(node.right !== null) queue.push(node.right);
}
res.push(temp);// 将一层的节点值加入到答案数组中
}
return res;
};
- 高效官方题解——就改了一处想法(如注释)但是效率一下子起来了!太优秀勒!
var levelOrder = function(root) {
const ret = [];
if (!root) {
return ret;
}
const q = [];
q.push(root);
while (q.length !== 0) {
const currentLevelSize = q.length;
ret.push([]);// 二维数组中添加一个一位数组来存这一层的节点值
for (let i = 1; i <= currentLevelSize; ++i) {
const node = q.shift();
ret[ret.length - 1].push(node.val);// 依次将节点值加入到队列末尾的那个数组(代表着当前层)中
if (node.left) q.push(node.left);
if (node.right) q.push(node.right);
}
}
return ret;
};
# 05 回溯
- 回溯算法的基本思想
从一条路往前走,能进则进,不能进则退回来,换一条路再试。——leetcode
这里的“回溯”二字,可以理解为是在强调上面提到的
DFS过程中“退一步重新选择”这个动作。这样想的话,DFS算法其实就是回溯思想的体现。
涉及剪枝操作的递归,我们一般称之为回溯。——某算法书籍
回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为 “回溯点”。 许多复杂的,规模较大的问题都可以使用回溯法,有“通用解题方法”的美称。——前端算法与数据结构面试
# 【1】解题模板
# 什么时候用回溯算法?
- 题目中暗示了一个/多个解,要求我们列出来每一个解的 具体内容
- 冷静分析下,可以转化为 树形逻辑模型求解
# 为什么用回溯算法?
- 递归与回溯的过程,本身就是 穷举 的过程
- 如果题目要求我们把每一个解都列举出来,那么自然就需要 穷举
- 穷举所有可能性时,对构建出来的搜索树进行恰当的剪枝(具体过程可以看下面题目的题解)
不让列举出解的所有情况,只问解的个数。
用动态规划。这可是个老大难问题!
- 背包问题
- 跑楼梯问题
- …
# 怎么用回溯算法?
- 分析问题要关注一个模型
- 树形逻辑模型
- 要能想出来这个模型
- 要会找树形模型中的 坑位
- 一个坑位对应树中的一层
- 每一层的处理逻辑(递归式的内容)一般都是一样的
- 树形逻辑模型
- 写代码要关注两个要点(所有递归问题都是关注这俩玩意儿)
- 递归式
- 树形逻辑模型每一层的处理逻辑即为递归式
- 递归边界
- 即为题目“每个答案的要求” / “坑位数量的边界”
- 递归式
伪代码总结下编码形式(这部分内容只是一个简单模板,具体情况还要结合题意(和根据题意分析出来的树形逻辑结构)来分析)——
const 具体问题 = function(入参){
定义辅助数组,缓存后面题目要用到的变量(数组长度啥的)
const path = [];// 定义路径栈——回溯思想中最重要的辅助
const res = [];// 结果数组,把path中的内容加入到res中,往往使用res.push(path.slice())
function dfs(递归参数){
if(达到递归边界){
处理边界逻辑,往往和path内容有关/向结果数组res中加入内容
return;
}
//
for(遍历“坑位”的可选值){
path.push(当前遍历到这个坑位的值);
处理坑位本身的相关逻辑
path.pop();
}
}
dfs(回溯起点);
}
# 【2】递归回溯经典题目
# 46. 全排列 (opens new window)
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
回溯法解题
const permute = function(nums) {
// 缓存数组的长度
const len = nums.length
// curr 变量用来记录当前的排列内容
const curr = []
// res 用来记录所有的排列顺序
const res = []
// visited 用来避免重复使用同一个数字
const visited = {}
// 定义 dfs 函数,入参是坑位的索引(从 0 计数)
function dfs(nth) {
// 若遍历到了不存在的坑位(第 len+1 个),则触碰递归边界返回
if(nth === len) {
// 此时前 len 个坑位已经填满,将对应的排列记录下来
res.push(curr.slice())
return
}
// 检查手里剩下的数字有哪些
for(let i=0;i<len;i++) {
// 若 nums[i] 之前没被其它坑位用过,则可以理解为“这个数字剩下了”
if(!visited[nums[i]]) {
// 给 nums[i] 打个“已用过”的标
visited[nums[i]] = 1
// 将nums[i]推入当前排列
curr.push(nums[i])
// 基于这个排列继续往下一个坑走去
dfs(nth+1)
// nums[i]让出当前坑位
curr.pop()
// 下掉“已用过”标识
visited[nums[i]] = 0
}
}
}
// 从索引为 0 的坑位(也就是第一个坑位)开始 dfs
dfs(0)
return res
};
# 78. 子集 (opens new window)
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
回溯法解题
// 入参是一个数组
const subsets = function(nums) {
// 初始化结果数组
const res = []
// 缓存数组长度
const len = nums.length
// 初始化组合数组
const subset = []
// 进入 dfs
dfs(0)
// 定义 dfs 函数,入参是 nums 中的数字索引
function dfs(index) {
// 每次进入,都意味着组合内容更新了一次,故直接推入结果数组
res.push(subset.slice())
// 从当前数字的索引开始,遍历 nums
for(let i=index;i<len;i++) {
// 这是当前数字存在于组合中的情况
subset.push(nums[i])
// 基于当前数字存在于组合中的情况,进一步 dfs
dfs(i+1)
// 这是当前数字不存在与组合中的情况
subset.pop()
}
}
// 返回结果数组
return res
};
# 77. 组合 (opens new window)
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
对搜索树进行剪枝,答案为红箭头串联起来的内容
const combine = function(n, k) {
// 初始化结果数组
const res = []
// 初始化组合数组
const subset = []
// 进入 dfs,起始数字是1
dfs(1)
// 定义 dfs 函数,入参是当前遍历到的数字
function dfs(index) {
if(subset.length === k) {
res.push(subset.slice())
return
}
// 从当前数字的值开始,遍历 index-n 之间的所有数字
for(let i=index;i<=n;i++) {
// 这是当前数字存在于组合中的情况
subset.push(i)
// 基于当前数字存在于组合中的情况,进一步 dfs
dfs(i+1)
// 这是当前数字不存在与组合中的情况
subset.pop()
}
}
// 返回结果数组
return res
};
# 06 排序问题
- 基础排序算法:
- 冒泡排序
- 插入排序
- 选择排序
- 进阶排序算法
- 归并排序
- 快速排序
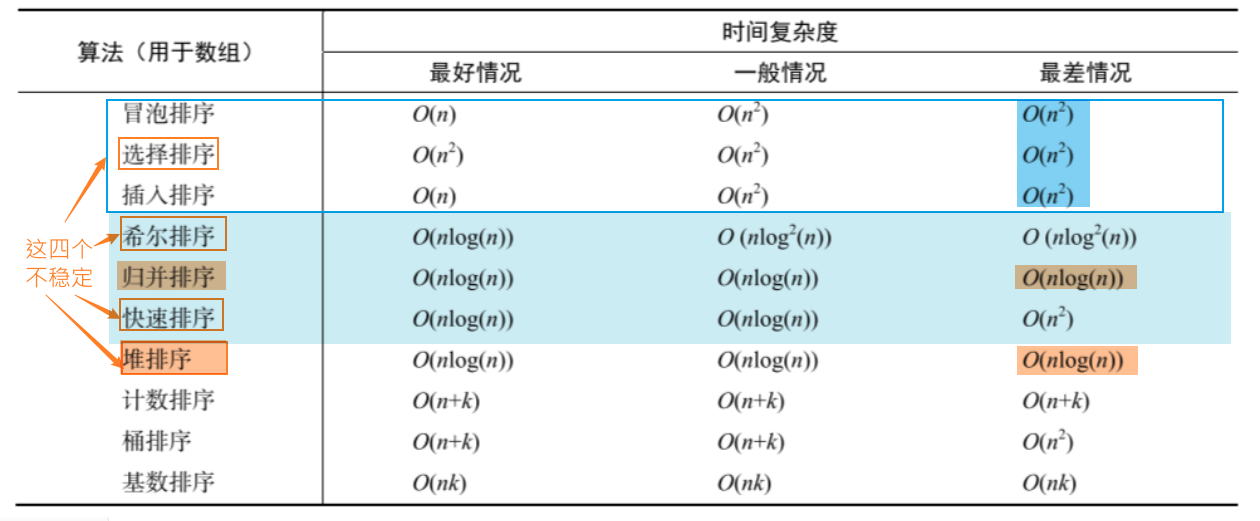
一个经典问题:选择排序的时间复杂度与数组的有序性无关~其实我觉得快排也算是无关吧(跟哨兵元素的选择有关捏),但是牛客的答案给到的是选择排序
顺带着复习了一遍选择排序的写法,双层循环,遇到更小的值则更新那一轮的最小值索引
function selectSort(arr) { // 缓存数组长度 const len = arr.length // 定义 minIndex,缓存当前区间最小值的索引,注意是索引 let minIndex // i 是当前排序区间的起点 for(let i = 0; i < len - 1; i++) { // 初始化 minIndex 为当前区间第一个元素 minIndex = i // i、j分别定义当前区间的上下界,i是左边界,j是右边界 for(let j = i; j < len; j++) { // 若 j 处的数据项比当前最小值还要小,则更新最小值索引为 j if(arr[j] < arr[minIndex]) { minIndex = j } } // 如果 minIndex 对应元素不是目前的头部元素,则交换两者 if(minIndex !== i) { [arr[i], arr[minIndex]] = [arr[minIndex], arr[i]] } } return arr }
# 【1】简单排序
- 冒泡排序
- 插入排序
- 选择排序
# 【2】快速排序
JavaScript&Java 超详细题解 填坑法快排~ - 排序数组 - 力扣(LeetCode) (leetcode-cn.com) (opens new window)
var sortArray = function(nums) {
quicksort(nums, 0, nums.length - 1); // 调用快排方法
return nums;
};
var quicksort = function(nums, low, high) {
if(low < high) {
let index = partition(nums, low, high); // 得到用来将数组分成两部分(左面全小于index 右面全大于index)的索引
quicksort(nums, low, index - 1); // 以第一轮得出的index为基准划分出左半区和右半区 对数组的左半区进行递归 将其全部变为有序
quicksort(nums, index + 1, high);// 同理左半区
};
};
var partition = function(arr, low, high) {
let pivot = arr[low]; // 选定第一个元素为基准值 把它拿出来 即为“挖坑”
while(low < high) {
// 【1】 挖了坑就需要填坑~从high指针开始向左找
while(low < high && arr[high] >= pivot) {
high--;
};
arr[low] = arr[high]; // 一旦找到比坑对应值pivot小的 就扔到low那侧的坑里
// 【2】 同【1】从low指针开始向右找填坑值
while(low < high && arr[low] < pivot) {
low++;
};
arr[high] = arr[low];// 一旦找到比坑对应值pivot大的 就扔到high那侧的坑里
//(刚刚这侧有一个值去填low那侧的坑了 所以出现了一个坑位~)
};
// 经过上面【1】【2】的不断迭代 low===high 此时这个位置即为基准位置
arr[low] = pivot;
return low; // 分区成功!返回定海神针~(此时low=high哦~)
};
# 07 动态规划
前端er如果了解dp的话肯定是大大滴加分项咯!比较常见的dp问题包括——
斐波那契数列、背包问题、爬楼梯问题、打家劫舍问题等,这些建议掌握嗷!
建议掌握的预备知识:递归——了解递归调用栈的一个原理,理解起来会更加轻松~
22/1/24更——动归不是洪水猛兽,一步步来理解,没那么难!
# 【1】轻松入门动态规划
# 入门-斐波那契数列
递归,记忆化搜索与动态规划_Keep Learning-CSDN博客 (opens new window)——感谢这篇很简单易懂的文章,帮我理解了
记忆化搜索+递归=(约等于)动态规划
- 记忆化搜索和递归大致思路一样,是一种自顶向下的思路
- 动态规划则是一种自底向上的思路
超简单的递归
let fb = function(n) {
if (n === 0) {
return 0
}
if (n === 1) {
return 1
}
return fb(n - 1) + fb(n - 2)
};
递归树如下,可以看到存在大量重复计算

记忆化搜索提升效率
const memo = []
const fb = function(n) {
if (n === 0) {
return 0;
}
if (n === 1) {
return 1;
}
// 这一步就是记忆化搜素新添的内容,使用一个数组来保存子问题的答案——这也正是动态规划的思想
if (memo[n]) {
return memo[n];
} else {
memo[n] = fb(n - 1) + fb(n - 2);
}
return memo[n];
};
简单的动归解法- 将原问题拆解成若干个子问题,同时保存子问题的答案——使得每个子问题只求解一次,最终获得原问题的答案~
let fib = function(n) {
let dp = [0, 1];
for (let i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
// console.log(dp);
return dp[n];
};
和上面的斐波那契数列异曲同工~
很easy!
# 70. 爬楼梯 (opens new window)
记忆化递归
理解记忆化递归 为自己的面试加分!
- 使用数组存储中间结果;
- 中间结果如果存在,则不要重复使用递归式进行计算!
由于递归太耗时,可以用记忆化递归避免重复的计算。 解题过程: 1.先对n为0这种特殊情况进行处理,然后n为1和2时直接return即可 2.memo数组:存储中间结果,避免重复计算 3.接下来就是判断memo[n]是否存在,如果计算过即存在,直接返回,无需重复计算;若不存在,则进行递归计算,为前两个之和。 代码
const memo = []
var climbStairs = function(n) {
if(n === 0) return 1
if(n <= 3) return n
// 记忆化递归 避免重复计算
if(memo[n]) {
return memo[n]
} else {
memo[n] = climbStairs(n-1) + climbStairs(n-2)
}
return memo[n]
}
经典动归问题
分成多个子问题,爬第n阶楼梯的方法数量,等于 2 部分之和
爬上 n-1 阶楼梯的方法数量
爬上 n-2 阶楼梯的方法数量
动态规划的转移方程为:dp[i] = dp[i - 1] + dp[i - 2];简单地使用动归求解(这里没必要使用递归这种时间复杂度较高的方法,除非用了记忆化递归~)
var climbStairs = function(n) {
const dp = [];
dp[0] = 1;
dp[1] = 1;
for(let i = 2 ; i <= n ; i++){
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n]
};
时间复杂度与空间复杂度都为O(N)
- 使用滚动数组(空间复杂度为1)实现动态规划(而不是使用空间复杂度为N的递归)
- 这也是官方题解的第一种方法(其他数学方法我退缩了XD)
- 这也是官方题解的第一种方法(其他数学方法我退缩了XD)

var climbStairs = function(n) {
let p = 0, q = 0, r = 1;// 初始化dp[0] dp[1] dp[2]
for (let i = 1; i <= n; i++) {
// 利用滚动数组达到O(1)空间复杂度的动归
p = q;
q = r;
r = p + q;
}
return r;
};
# 【2】使用动态规划解决复杂问题
# 53. 最大子序和 (opens new window)
很好的一篇题解,把思想说得蛮清楚
经典动态规划问题(理解「无后效性」) (opens new window)
# 08 前缀和
# 09 位运算
# 【1】位运算基础知识
# 按位与 a & b
【1】a b转换为二进制【2】进行按位运算 “且”的规则
0&0=0;
0&1=0;
1&0=0;
1&1=1;
- 利用这个特性可以快速判断一个数字是否为奇数(最后一个二进制是否为1)
(5 & 1) === 1;// true
(4 & 1) === 1;// false
# 按位或 a | b
【1】a b转换为二进制【2】进行按位运算 “或”的规则
0|0=0;
0|1=1;
1|0=1;
1|1=1;
# 异或 a ^ b
很有用的运算符!! 【1】a b转换为二进制【2】进行按位运算 “相同的数异或得0 任何数与0异或等于本身”的规则
// 二进制
0^0=0 1^1=0
0^1=1 1^0=1
// 十进制
6 ^ 6 = 0
0 ^ 666 = 666
两个经典用法
找出没有重复得数(一组数,都是成对的,只有一个落单的)进行全部异或运算最终结果即为落单那个数
1^2^3^4^5^1^2^3^4 = (1^1)^(2^2)^(3^3)^(4^4)^5= 0^0^0^0^5 = 5// 异或支持交换律和结合律~不使用额外得辅助变量 交换两个数x y的位置
x = x ^ y; y = x ^ y; x = x ^ y;
# 短路运算符 逻辑与 a && b
a 和 b都为真 才返回true
进行位运算时
0 && 6 = 0;// 发生短路(有一个结果为假)
6 && 8 = 8;
8 && 6 = 6;
6 && 7 && 8 = 8;// 两个都为true才不会发生短路 返回最后一个值
- 优先级比||高
3 || 2 && 5 || 0 = 3
// 先计算 2&&5=5 然后计算 3||5=3 最后得到 3||0=3
# 短路运算符 逻辑或 a || b
- a与b有一个为真 返回true
- 进行位运算时
0 || 0 = 0;// 结果为假时,返回第二个为假的值0
6 || 4 = 6;
4 || 6 = 4;// 结果为真时,返回第一个为真的值
6 || 0 = 6;// 因为是短路,所以前面出现一个true,不看后面直接停止
- 项目开发时,经常对一个数据进行逻辑或运算避免其报错
let obj = xxx || {}
# 【2】位运算经典应用
# 找出排序数组中只出现一次的数字&延伸题目
# 540. 有序数组中的单一元素 (opens new window)
同剑指 Offer II 070. 排序数组中只出现一次的数字 (opens new window) 一样
我的题解——[JavaScript]异或、二分搜索(全体二分查找乱序数组&偶数二分查找有序数组)注释齐全 (opens new window)
# 异或快捷解决
540题中英文版有规定 :Your solution must run in
O(log n)time andO(1)space. 所以这个方法仅供了解主要考察二分法!
var singleNonDuplicate = function(nums) {
let res;
for(let i = 0; i < nums.length; i++){
res ^= nums[i];
}
return res;
};
# 再优化,二分法(面试重点)
这里的第一个关键点是先把四种情况列出来!
参考官方题解
例子 1:中间元素的同一元素在右边,且被 mid 分成两半的数组为偶数。
我们将右子数组的第一个元素移除后,则右子数组元素个数变成奇数,我们应将 lo 设置为 mid + 2。
例子 2:中间元素的同一元素在右边,且被 mid 分成两半的数组为奇数。
我们将右子数组的第一个元素移除后,则右子数组的元素个数变为偶数,我们应将 hi 设置为 mid - 1。
例子 3:中间元素的同一元素在左边,且被 mid 分成两半的数组为偶数。
我们将左子数组的最后一个元素移除后,则左子数组的元素个数变为奇数,我们应将 hi 设置为 mid - 2。
例子 4:中间元素的同一元素在左边,且被 mid 分成两半的数组为奇数。
我们将左子数组的最后一个元素移除后,则左子数组的元素个数变为偶数,我们应将 lo 设置为 mid + 1。




然后就常规二分法做就行了~注意分情况讨论的细则即可!
var singleNonDuplicate = function(nums) {
// 定义双指针
let i = 0, j = nums.length - 1;
while(i < j){
// let mid = (i + j) >> 1;
// 为了防止大数溢出 建议这么写
let mid = i + (j - i >> 1)
// 此方法的关键——判断哪边为奇数的变量 要设置好
let isEven = (j - mid) % 2 == 0;
// 如果j-mid为偶数 则去除中间两个值相同的元素并跳过它们之后,两指针(包括两指针)之间有奇数个元素,
// 也就是单个的元素一定在这之间
if(nums[mid] === nums[mid - 1]){
if(isEven){
// 在左边
j = mid - 2;
}
else{
i = mid + 1;
}
}
else if(nums[mid] === nums[mid + 1]){
if(isEven){
// 在右边
i = mid + 2;
}
else{
console.log("last j", j)
j = mid - 1;
}
}
else{
return nums[mid];
}
}
return nums[i];
};
怎么说呢,双指针的题,多画图就完事了!
时间复杂度 O(logn),相比于暴力循环(包括异或),每次迭代将搜索空间缩减了一半!
# 进一步优化,仅对偶数索引进行二分搜索
最佳实践
var singleNonDuplicate = function(nums) {
let i = 0, j = nums.length - 1;// 数组长度必为奇数,所以一前一后两个元素下标为偶数
while(i < j){
let mid = i + ((j - i) >> 1);
if(mid % 2 === 1){
// mid为奇数则-1变为偶数 则mid现在必为“边缘” 不必再分四种情况来讨论
// 这就是仅对偶数索引进行二分搜索!
mid--;
}
if(nums[mid + 1] === nums[mid]){
// 去除mid那一对数之后,左侧数必为偶数,右侧数必为奇数,继续去紧挨着那对数的右边1个找
i = mid + 2;
}
else{
// 去除mid那一对数之后,左侧数为奇数,右侧数必为偶数,继续去紧挨着那对数的左边1个找
j = mid;// 此时mid已经在原基础上左移一位了 所以j直接放在mid这个位置即可
}
}
return nums[i];
};
- 时间复杂度:O(log n/2) = O(logn)。我们仅对元素的一半进行二分搜索。
# 剑指 Offer 56 - I. 数组中数字出现的次数 (opens new window)
# 位运算-分组异或
这个分组的方法就很灵性。
var singleNumbers = function(nums) {
let n = 0;
// 01 n 为 两个单独数a b的乘积
// 接下来(02中)使用与运算
// 与运算特点 二进制中只有6&6 = 6 6&0 = 0&0 =0
for(let num of nums){
n ^= num;
}
// 02 m可以保证这个数组中单身的两个数a b中的一个可以不被它抵消掉
// 也就是 m&a = 0 m&b != 0
let m = 1;
while((n & m) === 0){
// 只要n&m不为0 就一直让m左移,直到m可以抵消掉a与b中的一个
m <<= 1;
}
// 03 接下来使用m把两个单独的数分在两堆 并分组
let x = 0, y = 0;
for(let num of nums){
if((num & m) === 0){
x ^= num;
}
else{
y ^= num;
}
}
return [x, y];
};
看不懂我这个解释(或者觉得太大白话) 可以看看 K神的题解 (opens new window)
# 10.滑动窗口
# 滑动窗口模板
分享滑动窗口模板,秒杀滑动窗口问题 - 最大连续1的个数 III - 力扣(LeetCode) (leetcode-cn.com) (opens new window)
# 经典题目
# 3. 无重复字符的最长子串 (opens new window)
滑窗模板题&经典题
采用队列&滑窗思想来解题:
将新字符加入队列,重复字符出队。比如——
队列里面有QAQbc 几个字符,第二个Q要入队的时候发现队列里面已经有a了,则去掉队列里的QA,再将新的Q插入,推动窗口向前。
function lengthOfLongestSubstring(s: string): number {
const len = s.length;
if (len < 2) return len;
let max = 0, cur = []; // 创建队列
for (let i = 0; i < len; i++) {
const idx = cur.indexOf(s[i]); // 判断当前字符是否在队列中存在
if (idx !== -1) {
max = Math.max(max, cur.length); // 更新z
cur.splice(0, idx + 1); // 重复字符部分出队,因为不能返回子序列 所以把之前的全去掉——滑窗思想
}
cur.push(s[i]); // 新字符入队
}
return Math.max(cur.length, max);
};
# 1004. 最大连续1的个数 III (opens new window)
好题!配合下面的动图题解 用来入门滑窗再合适不过了~
分享滑动窗口模板,秒杀滑动窗口问题 - 最大连续1的个数 III (opens new window)
# 2024. 考试的最大困扰度 (opens new window)
# 438. 找到字符串中所有字母异位词 (opens new window)

非常棒的一题
- 很明显的(第一次做完全没看出来,惭愧!)滑动窗口的思想
- 利用一维数组模拟哈希表(之前我一看见哈希表二话不说直接new Map()…)
来看个图 很清晰了就 来源 (opens new window)
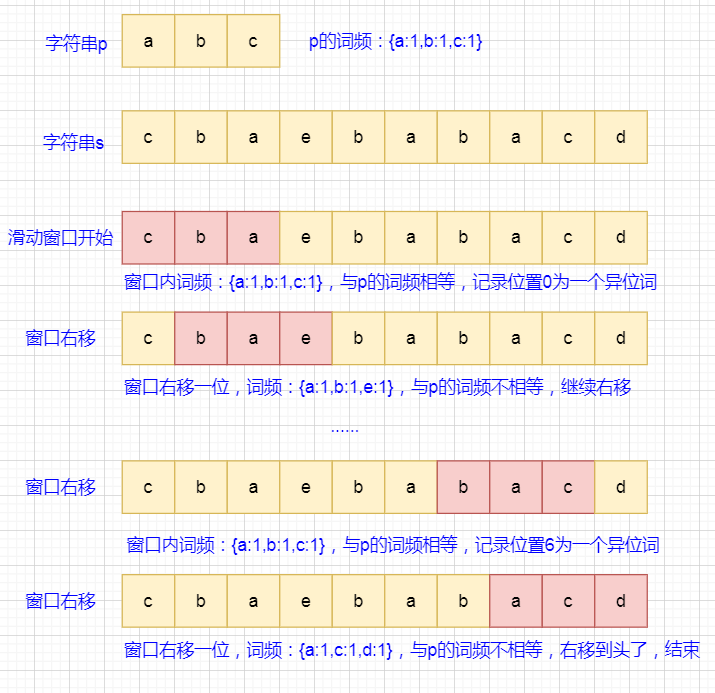
注释齐全,这个方法是最最基础的固定窗口大小的滑动窗口,再困难一些的有窗口大小变动的76. 最小覆盖子串 (opens new window),嗯是个hard🥺
var findAnagrams = function(s, p) {
// 在滑动窗口中维护每种字母的数量(通过哈希表,注意哈希表不一定用Map数据结构哈,一维数组也ok 如本题经典的26个坑的哈希表——数组索引即为“键”,对应数组值即为“值”)
const sLen = s.length, pLen = p.length;
if(sLen < pLen) {
return [];// 这个判空一下子没想到XD
}
const ans = [];
// 一维哈希表初始化下,初始化值为0
const hashS = new Array(26).fill(0);
const hashP = new Array(26).fill(0);
// 01 先建立起第一个窗口,顺便将hashP这个哈希表建立好
for(let i = 0; i < pLen; i++) {
hashS[s[i].charCodeAt() - 'a'.charCodeAt()]++;
hashP[p[i].charCodeAt() - 'a'.charCodeAt()]++;
}
if(hashS.toString() === hashP.toString()) {
ans.push(0)
}
// 02 将滑窗往后推,每轮推动将滑窗第一个位置的元素值-1,将滑窗末端下一个位置的元素值+1
for(let i = 0; i < sLen - pLen; i++) {
// 滑动窗口的推动
hashS[s[i].charCodeAt() - 'a'.charCodeAt()]--;
hashS[s[i + pLen].charCodeAt() - 'a'.charCodeAt()]++;
if(hashS.toString() === hashP.toString()) {
ans.push(i + 1)
}
}
return ans;
};
# 11.二分查找
# 12.随机算法
# 数组的洗牌随机抽样
# 384. 打乱数组 (opens new window)
最后一张牌跟随机一张交换位置 然后是倒数第二张 直到最后一张没“洗”过的(其实有可能已经变过位置勒 但是就是为了让每个索引处的都调整一下 公平嘛~)
var Solution = function(nums) {
this.nums = nums;
this.original = this.nums.slice();
};
Solution.prototype.reset = function() {
// 重设数组到它的初始状态并返回
this.nums = this.original.slice();
return this.nums;
};
Solution.prototype.shuffle = function() {
// 洗牌算法 最终返回数组随机打乱的结构
for (let i = 0; i < this.nums.length; ++i) {
const j = Math.floor(Math.random() * (this.nums.length - i)) + i;
[this.nums[i], this.nums[j]] = [this.nums[j], this.nums[i]]
}
return this.nums;
};
# 链表的蓄水池抽样算法
# 382. 链表随机节点 (opens new window)
链表随机节点 - 链表随机节点 (opens new window)

var Solution = function(head) {
this.head = head
};
Solution.prototype.getRandom = function() {
let i = 1, ans = 0
for (let node = this.head; node !== null; node = node.next) {
if (Math.floor(Math.random() * i) === 0) {
ans = node.val
}
i++
}
return ans
};