🦄JavaScript
# 🦄JavaScript
JS部分的知识需要删减一下呐!好多是初学时期写的XD
# JS知识体系
前端人吃饭的家伙~ 回头慢慢补充吧
- ES6新增知识
- 工作中写代码都是ES6语法了,所以这部分很重要~
- 解构赋值
- 新增的API
- JavaScript-API
- 数组相关
- 字符串相关
- 对象相关
- JSON.stringify() 灵活处理不同类型数据的能力
- 函数
- 原型
- 作用域、闭包问题
- 浏览器中的JS
- DOM API
- 事件循环机制
- 异步编程
- Promise
- async await语法糖
- 模块化编程
# JS学习资源
- 《JS高级程序设计(第四版)》
- ES6 入门教程 - ECMAScript 6入门 (ruanyifeng.com) (opens new window)
- 我更倾向于用这个带目录的阅读器读阮大的这本必学书籍——ECMAScript 6 入门 - 《阮一峰 ECMAScript 6 (ES6) 标准入门教程 第三版》 (opens new window)
- (建议收藏)原生JS灵魂之问, 请问你能接得住几个?(上) (opens new window)
- MDN Web Docs (mozilla.org) (opens new window)
- 《你不知道的JS(上、中、下)》
# JS基础
# 0.1 + 0.2 === 0.3 嘛?为什么?
==答==:
不等于…
本质原因是“二进制模拟十进制进行运算时的精度问题”
深入了说说,JS使用Number类型来表示数字(整数/浮点数皆是如此)。遵循 IEEE 754 标准,通过 64 位来表示一个数字(1 + 11 + 52)。将0.1、0.2转换给计算机看要用二进制,这时由于尾数存在无限循环,所以加起来的值是不严格相等的。
0.1 -> 0.0001100110011001...(无限循环) 0.2 -> 0.0011001100110011...(无限循环) // 由于IEEE 754尾数位数限制,需要将后面多余的位截掉 造成了精度损失- 这是一种“精度损失”的现象,可能出现在 进制转化和对阶运算过程中
- 只要这两步中产生了精度损失,计算结果肯定会出现偏差
- 这是一种“精度损失”的现象,可能出现在 进制转化和对阶运算过程中
为何使用64位表示一个数字?
JavaScript使用Number类型表示数字(整数和浮点数),遵循 IEEE 754 (opens new window) 标准 通过64位来表示一个数字(1 + 11 + 52)
通过图片具体看一下数字在内存中的表示
图片文字说明
- 第0位:符号位,0表示正数,1表示负数(s)
- 第1位到第11位:储存指数部分(e)
- 第12位到第63位:储存小数部分(即有效数字f)
为什么 x=0.1 能得到 0.1?
因为这个 0.1 并不是真正的0.1,经过了精度运算
0.10000000000000000555.toPrecision(16) // 返回 0.1000000000000000,去掉末尾的零后正好为 0.1 // 但来一个更高的精度: 0.1.toPrecision(21) = 0.100000000000000005551
如何解决精度问题?
【1】
function add(num1, num2) { const num1Digits = (num1.toString().split('.')[1] || '').length; const num2Digits = (num2.toString().split('.')[1] || '').length; const baseNum = Math.pow(10, Math.max(num1Digits, num2Digits)); return (num1 * baseNum + num2 * baseNum) / baseNum; } // 缺点:对大数的支持不好【2】
使用三方库
涉及勒更多部分,觉得没吃饱的可以再往下看看
一旦你掌握了这个过程,能让你更深刻的认识到其中的存储、运算机制。
# 七种基本数据类型,一种引用数据类型
写过一篇文章 重学数据(类型)、变量、内存 (opens new window),
聊了一下这几个数据类型要如何通过typeof instanceof判定;
聊了一下内存的问题——
- 基本数据类型赋值给变量,变量存在栈中;
- 引用数据类型赋值给变量,变量存在栈中,而对象保存在堆中,变量指向堆~

基本数据类型

var a = 1, b = 2;
function test(pre, cur){
pre = "hello world";// 函数作用域中的pre为"hello world"
cur = 666;// 函数作用域中的cur为666
// 这二位都不会影响到a b
}
function test2(){
a = a+1;
b = 666;
}
test(a, b);
console.log(a, b);// 1 2
test2();
console.log(a, b);// 2 666
- 引用类型
Object
# 运算符优先级 (opens new window)
# parseInt & parseFloat
首先明确定义
parseInt(string, radix)- radix范围2-32,string不能大于radix
- 例外
parseInt(n, 0) = n
parseInt函数将其第一个参数转换为一个字符串,对该字符串进行解析,然后返回一个整数或 NaN。
第二个参数为其对应的进制(默认是十进制哈)
注意如果第一个参数从左到右数,遇到字符就会舍弃字符+字符后面的内容
parseInt('0001', 2);// 1 parseInt('00x1111', 2);// 0 parseInt('0011x11', 2);// 3
parseInt('123xxx', 5) // 先把'123xxx'转换为'123' 将'123'看作5进制数,返回十进制数38 => 1*5^2 + 2*5^1 + 3*5^0 = 38
parseFloat
parseFloat() 函数解析一个参数(必要时先转换为字符串)并返回一个浮点数。
parseFloat('5556.6www');// 5556.6
这里一个有趣的应用
var a = ["88","66"];
// 将a数组转换为数值型可以简单地这样做
a.map(parseFloat);// [88,66]这里其实我也不知道为啥可以XD
//a.map(parseInt) 返回就是 [88,NaN]🥺
// 也可以常规一些~
a.map(x => parseInt(x));// .map(x => parseFloat(x))
# 字面量的概念
字面量可分为数字字面量、字符串字面量、数组字面量、表达式字面量、对象字面量、函数字面量。
- 数字(Number)字面量 可以是整数或者是小数,或者是科学计数(e)。
3.14
123e5
- 字符串(String)字面量 是使用单引号或双引号定义的字符串。
"John Doe"
- 表达式字面量:
5 + 6
5 * 10
- 数组(Array)字面量 定义一个数组:
[40, 100, 1, 5, 25, 10]
- 对象(Object)字面量 定义一个对象:
{firstName: "John", lastName: "Doe", age: 50, eyeColor: "blue"}
- 函数(Function)字面量 定义一个函数:
function myFunction(a, b) { return a * b; }
- 箭头函数中 使用括号返回对象的字面量形式
//加括号的函数体返回对象字面量表达式:
params => ({foo: bar})
# for…in (opens new window) for…of (opens new window)的用法&区别
- for in 遍历对象的键
- 注意:对象原型链上(继承得来)的属性也会被遍历到!

- for of 遍历可迭代对象 Array Map Set

这个好用欸!

# Array类型相关知识,及常见api
# 改变&不改变原数组的方法
- 改变原数组的方法
- 增删、改、查
- splice() 添加/删除数组元素
语法:arrayObject.splice(index,howmany,item1,.....,itemX) 参数: 1.index:必需。整数,规定添加/删除项目的位置,使用负数可从数组结尾处规定位置。 2.howmany:可选。要删除的项目数量。如果设置为 0,则不会删除项目。如果不设置则会删除index及其之后的所有元素。 3.item1, ..., itemX:可选。向数组添加的新项目。 返回值: 如果有元素被删除,返回包含被删除项目的新数组。
sort() 数组排序
pop() 删除一个数组中的最后的一个元素
shift() 删除数组的第一个元素
push() 向数组的末尾添加元素
unshift() 向数组的开头添加一个或更多元素
reverse() 颠倒数组中元素的顺序
copyWithin() 指定位置的成员复制到其他位置
语法:array.copyWithin(target, start = 0, end = this.length) 参数: 1.target(必需):从该位置开始替换数据。如果为负值,表示倒数。 2.start(可选):从该位置开始读取数据,默认为 0。如果为负值,表示倒数。 3.end(可选):到该位置前停止读取数据,默认等于数组长度。如果为负值,表示倒数。 返回值: 返回当前数组。
- fill() 填充数组
语法:array.fill(value, start, end) 参数: 1.value必需。填充的值。 2.start可选。开始填充位置。 3.end可选。停止填充位置 (默认为 array.length) 返回值: 返回当前数组。
- 不改变原数组的方法
- 查值、合并、拷贝等API
- slice() 浅拷贝数组的元素
语法:array.slice(begin, end); 参数: 1.begin(可选): 索引数值,接受负值,从该索引处开始提取原数组中的元素,默认值为0。 2.end(可选):索引数值(不包括),接受负值,在该索引处前结束提取原数组元素,默认值为数组末尾(包括最后一个元素)。 返回值: 返回一个从开始到结束(不包括结束)选择的数组的一部分浅拷贝到一个新数组对象,且原数组不会被修改。
join() 数组转字符串
concat() 合并两个或多个数组
语法:var newArr =oldArray.concat(arrayX,arrayX,......,arrayX) 参数: 1.arrayX(必须):该参数可以是具体的值,也可以是数组对象。可以是任意多个。 返回值: 返回返回合并后的新数组。
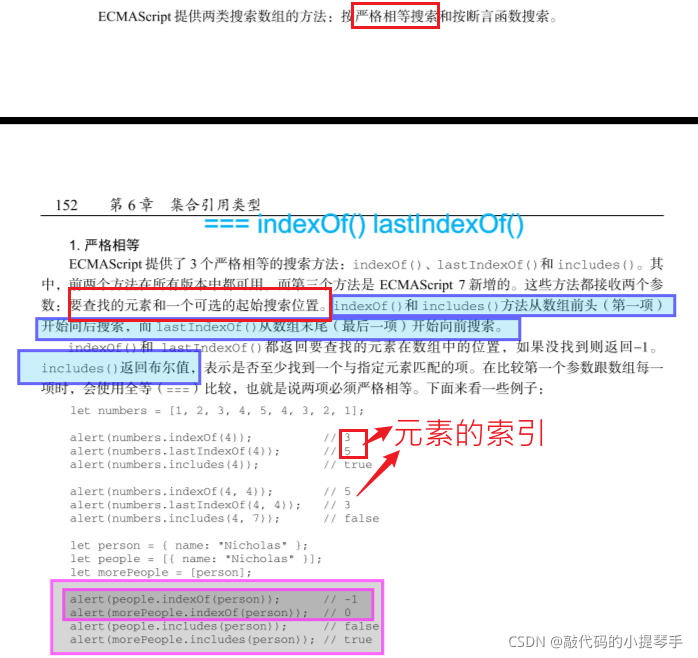
- indexOf() 查找数组是否存在某个元素
语法:array.indexOf(searchElement,fromIndex) 参数: 1.searchElement(必须):被查找的元素 2.fromIndex(可选):开始查找的位置(不能大于等于数组的长度,返回-1),接受负值,默认值为0。 返回值: 返回下标
- lastIndexOf() 查找指定元素在数组中的最后一个位置
语法:arr.lastIndexOf(searchElement,fromIndex) 参数: 1.searchElement(必须): 被查找的元素 2.fromIndex(可选): 逆向查找开始位置,默认值数组的长度-1,即查找整个数组。 返回值: 方法返回指定元素,在数组中的最后一个的索引,如果不存在则返回 -1。(从数组后面往前查找)
- includes() 查找数组是否包含某个元素
语法:array.includes(searchElement,fromIndex=0) 参数: 1.searchElement(必须):被查找的元素 2.fromIndex(可选):默认值为0,参数表示搜索的起始位置,接受负值。正值超过数组长度,数组不会被搜索,返回false。负值绝对值超过长数组度,重置从0开始搜索。 返回值: 返回布尔
# 判断是否为数组的方法
- 通过Object.prototype.toString.call()做判断
- 这个考虑较全面,但是用isArray也是ok的~
Object.prototype.toString.call(obj).slice(8,-1) === 'Array';
- 通过原型链做判断
obj.__proto__ === Array.prototype;
- 通过construtor来判断
obj.constructor === Array
- 通过ES6的Array.isArray()做判断
Array.isArray(obj);
- 通过instanceof做判断
obj instanceof Array
- 通过Array.prototype.isPrototypeOf
Array.prototype.isPrototypeOf(obj)
# Array API总结
ES5新增的Array API
下面这些内容大部分为红宝书的内容
# 1.创建数组的静态方法 from of
from()用于将 类数组结构转换为数组实例,而 of()用于将一组参数转换为数组实例
# 2.数组空位
由于行为不一致和存在性能隐患,因此实践中要避免使用数组空位。
如果确实需要空位,则可以显式地用 undefined 值代替。
# 3.length属性
数组 length 属性的独特之处在于,它不是只读的。通过修改 length 属性,可以从数组末尾删除 / 添加元素
# 4.数组检测
一个经典的 ECMAScript 问题是判断一个对象是不是数组。在只有一个网页(因而只有一个全局作用域)的情况下,使用 instanceof 操作符就足矣:
使用
instanceof的问题是假定只有一个全局执行上下文。如果网页里有多个框架,则可能涉及两 个不同的全局执行上下文,因此就会有两个不同版本的 Array 构造函数。如果要把数组从一个框架传给另一个框架,则这个数组的构造函数将有别于在第二个框架内本地创建的数组。
为解决这个问题,ECMAScript提供了 Array.isArray()方法。这个方法的目的就是确定一个值是 否为数组,而不用管它是在哪个全局执行上下文中创建的
# 5.迭代器方法 keys values entries
在 ES6 中,Array 的原型上暴露了 3 个用于检索数组内容的方法:keys()、values()和 entries()。keys()返回数组索引的迭代器,values()返回数组元素的迭代器,而 entries()返回索引/值对的迭代器:
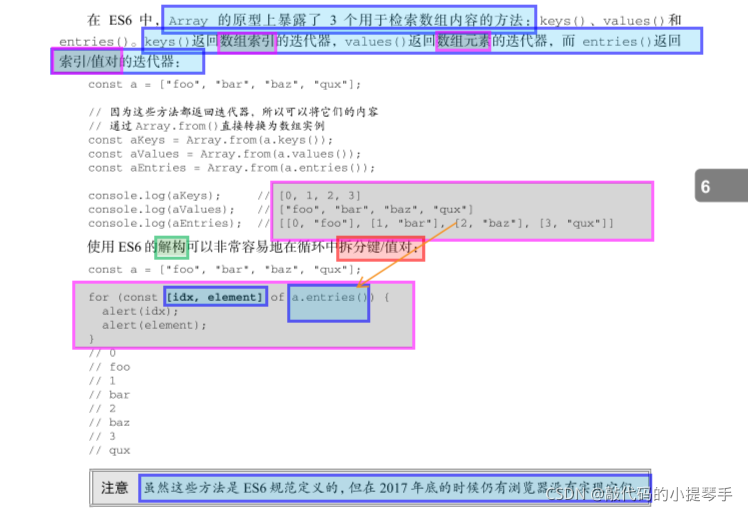
# 6.数组复制与填充问题

const zeros = [0,0,0,0,0];
//zeros.fill(填充数字,填充索引起始,填充索引结束前一位);
zeros.fill(7, 1, 3);
console.log(zeros);//[0,7,7,0,0]
let ints,
reset = {} => ints =[0,1,2,3,4,5,6,7,8,9];
//ints.copyWithin(插入位置的索引,复制的索引起始,复制的索引结束前一位);
ints.copyWithin(4,0,3);//[0,1,2,3, 0,1,2, 7,8,9]
# 7.数组->字符串
得到——以逗号分隔数组值的字符串
toLocaleString()toString()数组.valueOf()
得到——以传入参数分割数组值的字符串
而
包装对象实例.valueOf()则返回包装对象实例对应的原始类型的值new Number(123).valueOf() // 123 new String('abc').valueOf() // "abc" new Boolean(true).valueOf() // true
join("xxx")
# 8.数组的栈方法

# 9.数组的队列方式
就只有 入队列的方法与栈不同 其他方法是一样的
使用Array.prototype.shift()插入到队头
# 10.数组排序方法 sort
sort 这个sort有个坑 所以一般不直接用

注意字符串排序的小细节
根据ASCII值来比较 所以小写字母a会在大写字母Z后面

# 11.数组的操作方法-增加元素 单独切一段元素 插入元素 concat slice splice
concat()

一个很有意思的用法——用来合并多个数组&数字(例子来自MDN)
var alpha = ['a', 'b', 'c'];
var alphaNumeric = alpha.concat(1, [2, 3]);
console.log(alphaNumeric);
// results in ['a', 'b', 'c', 1, 2, 3]
// 可以用来连接数字/数组
slice()

splice()

简单来说就是删除/插入 然后根据这俩功能自然就可以做出来替换咯~ 来看看JS

# 12.搜索数组中元素的位置 indexOf
好用~ 做个数组去重 可以用这个API来查元素位置
# 13.迭代方法 - 各种高级操作 filter map forEach
超级好用的几个方法!
every()some()filter()

map()forEach()

# 14.归并方法 reduce
reduce()
这里的reduce的第一个参数 prev要注意
如果求和时 一般会给其起名为total 用于存储截至此时的和
我比较习惯给它取名叫 acc —— accumulator 累加器~

# 15.Map集合类型的基本API
明确Map实例的格式 为 键值对
const map = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
])
- set() 添加键值对
- get() 获得某个键的值
- has() 查询是否有这个键
.size()获取键值对数量- delete() 删除某个键值对
- clear() 清除映射实例中的所有键值对
- entries() (opens new window) 返回一个新的包含
[key, value]对的Iterator对象,返回的迭代器的迭代顺序与Map对象的插入顺序相同。 - forEach() (opens new window) 按照插入顺序依次对
Map中每个键/值对执行一次给定的函数 - values() (opens new window)它包含按顺序插入Map对象中每个元素的value值。
举例:

另外 与Object只能使用数值、字符串、符号作为键不同
Map可以使用任何JS数据类型作为键!!(这也是为啥ES6要创键这个集合类型)
另外注意 Map实例对象2个有趣的特性:
- 一个key放入多个value —— 覆盖原先的value
var m = new Map(); m.set('Adam', 67); m.set('Adam', 88); m.get('Adam');//88可以看出 key是不允许重复的!这也符合哈希表特性
但是重复了也不会出错 自动就覆盖掉了
- 值重复就没啥事儿(那肯定的嘛)

# 16.迭代Map实例(按照插入顺序)
又看到了 .entries() 迭代器方法!
——可以返回key value
# 17.Set集合类型的基本API
跟Map的大多数API 和 行为 都是共有的
也是一组key的集合,但不存储value。
- 要创建一个
Set,需要提供一个Array作为输入,或者直接创建一个空Set:
var s1 = new Set(); // 空Set
var s2 = new Set([1, 2, 3]); // 含1, 2, 3
//其实跟map的初始化方法是一样的 就是初始化内容不同而已
由于key不能重复,所以,在Set中,key是无法像Map实例中一样 可以覆盖的!
.size—— set的长度has()判断有没有这个元素clear()add()与map的set添加一组键值对不同 set只会添加一个独一无二的元素
# 18.apply方法的使用
通过 apply() 方法 (opens new window),您能够编写用于不同对象的方法。(与call()方法非常类似,只有传参时有区别——apply方法传参为对象)
- 方法重用
var person = {
fullName: function() {
return this.firstName + "调用成功" + this.lastName;
}
}
var person1 = {
firstName:"Bill",
lastName: "Gates"
}
person.fullName.apply(person1); // Bill调用成功Gates
var person = {
fullName: function(city, country) {
return this.firstName + " " + this.lastName + "," + city + "," + country;
}
}
var person1 = {
firstName:"Bill",
lastName: "Gates"
}
// 还可以传参进去哈!与call不同于参数的类型 为 数组
person.fullName.apply(person1, ["Seatle", "USA"]); // Bill Gates,Seatle,USA
- 可用于在数组上模拟max方法
您可以使用 Math.max() 方法找到(数字列表中的)最大数字:
由于 JavaScript 数组没有 max() 方法,因此您可以应用 Math.max.apply() 方法。
Math.max(1,2,3);
let arr = [1,2,3]
Math.max.apply(null, arr); // 也会返回 3 注意:第一个参数填啥没影响的,本次使用中没他事儿~
- JavaScript 严格模式
在 JavaScript 严格模式下,如果 apply() 方法的第一个参数不是对象,则它将成为被调用函数的所有者(对象)。
在“非严格”模式下,它成为全局对象。
# 19.浅复制数组的一部分到同一数组的另一位置 copyWithin() (opens new window)
copyWithin() 方法浅复制数组的一部分到同一数组中的另一个位置,并返回它,不会改变原数组的长度。
const array1 = ['a', 'b', 'c', 'd', 'e'];
// copy to index 0 the element at index 3
console.log(array1.copyWithin(0, 3, 4));
// expected output: Array ["d", "b", "c", "d", "e"]
// copy to index 1 all elements from index 3 to the end
console.log(array1.copyWithin(1, 3));
// expected output: Array ["d", "d", "e", "d", "e"]
神奇的方法~
为啥用呢 看看JS数据结构与算法中怎么说~

# 20.Array.of() (opens new window)创建新数组,复制一维数组的方法
Array.of() 方法创建一个具有可变数量参数的新数组实例,而不考虑参数的数量或类型。
Array.of() 和 Array 构造函数之间的区别在于处理整数参数:Array.of(7) 创建一个具有单个元素 7 的数组,而 Array(7) 创建一个长度为7的空数组(**注意:**这是指一个有7个空位(empty)的数组,而不是由7个undefined组成的数组)。
Array.of(7); // [7]
Array.of(1, 2, 3); // [1, 2, 3]
Array(7); // [ , , , , , , ]
Array(1, 2, 3); // [1, 2, 3]
可以用来浅复制一个数组
官方文档中没有提到用of方法进行复制的操作
但是雀氏可以~ 下面额尝试可以清楚看出来复制为浅复制!

# 经典数组去重
22/3/20 美团一面碰到一个极为刁钻的去重
# 带有
NaN{}的数组去重聊了四十分钟的项目&基础 本来说写两道题 没想到一道题都没写完美 凉凉的赶脚~
const arr = [1, 1, '666', '666', null, null, undefined, undefined, NaN, NaN, {}, {}] Array.prototype.uniq = function() {}# 最开始的错误思想
——仅能用于基本数据类型的查重
用了三种思路 【1】Set数据结构快捷完成,【2】排序后冒泡比较,【3】用每轮查找都用
indexOf进行比对发现有个坑没排掉 要对
{}NaN这俩不属于基本数据类型的元素 进行单独的去重处理 在牛客的OJ上一紧张把这事儿给忘了经过测试,
indexOf效率最高
正解👇
利用
hasOwnProperty + filter + 额外存储空间
let arr=[{}, {}, NaN, NaN, {a: 1}, {a: 1}, {a: 1, b: 666}, {a: 1, b: 666}, [], [], 666, '666', '666', 666, false, false]; Array.prototype.uniq = function() { const uniqObj = {}; return this.filter((item) => { let uniqItem = typeof item + JSON.stringify(item); return uniqObj.hasOwnProperty(uniqItem) ? false : uniqObj[uniqItem] = true; // obj[attr] = true 返回true obj[attr] = false 返回false 22/3/20的sfz并不知道这个知识点,,, }) } console.log(arr.uniq()); // 测试成功~ 爽~~
可以写一下经典的 217. 存在重复元素 (opens new window)
数组去重12种方法 (opens new window) - 这边里利用对象实现去重的思路挺有意思的 亮点是不用辅助数组 直接在原数组上操作 数组熟练度++
# 利用辅助对象模拟哈希表+(不借助辅助数组)在原数组上直接去重
let arr = [12,1,12,3,1,88,66,9,66];
function unique(arr) {
let obj = {};
for(let i=0;i<arr.length;i++){
let cur = arr[i];
if(obj[cur]){// 如果当前遍历到的元素之前碰到过,进入逻辑把它从arr中删了
// 01 删除重复元素法一
arr.splice(i,1);// 导致数组塌陷——用i--的方式规避数组塌陷!
// 删除重复元素法二
// arr[i]=arr[arr.length-1];// 重复元素的坑给数组最后一个元素勒
// arr.length--;// 删除最后一项
console.log(i);// 2 4 6
// 02 对重复元素进行操作之后 手动将索引值-1 保证数组的每一项都被遍历~
i--;// 注意!删了这个元素之后它之后的数组元素都提前勒!要倒回去一个索引获得原本的下一个数组元素。
continue;// 跳过obj[cur] = cur,给i加上1 进入下一轮循环(其实这句不加也无所谓,给对象重复赋值也没啥影响~)
}
obj[cur]=cur;// 给obj新增键值对;属性名和属性值是一样的
}
}
unique(arr);
console.log(arr);// 法一答案 [12, 1, 3, 88, 66, 9] 法二答案 [12, 1, 66, 3, 9, 88]
# 经典数组乱序
# 前端面试(算法篇) - 数组乱序 (opens new window)
写得挺好的 搭配 384. 打乱数组 (opens new window) 食用更佳
首先是伪随机的两种方法
- 随机取数
从原数组中随机抽取一个数,然后使用 splice 删掉该元素
function getRandomArrElement(arr, count) {
let res = []
while (res.length < count) {
// 生成随机 index
let randomIdx = (Math.random() * arr.length) >> 0;
// splice 返回的是一个数组
res.push(arr.splice(randomIdx, 1)[0]);
}
return res
}
上面生成随机 index 用到了按位右移操作符 >>
当后面的操作数是 0 的时候,该语句的结果就和 Math.floor() 一样,是向下取整
但位操作符是在数值表示的最底层执行操作,因此速度更快
// 按位右移
(Math.random() * 100) >> 0
// Math.floor
Math.floor(Math.random() * 100)
/* 这两种写法的结果是一样的,但位操作的效率更高 */
- 通过 sort 乱序
首先认识一下 Array.prototype.sort() (opens new window) 不了解的查看下 这个必须滚瓜烂熟
let arr = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'];
arr.sort((a, b) => 0.5 - Math.random());
但这并不是真正的乱序,计算机的 random 函数因为循环周期的存在,无法生成真正的随机数(力扣那题用这个方法也跑不通XD)
- Fisher–Yates shuffle 洗牌算法
这个方法太漂亮勒!
另外这个作者的写法也很漂亮!棒!
洗牌算法的思路是:
【1】先从数组末尾开始,选取最后一个元素,与数组中随机一个位置的元素交换位置
【2】然后在已经排好的最后一个元素以外的位置中,随机产生一个位置,让该位置元素与倒数第二个元素进行交换
以此类推,打乱整个数组的顺序
function shuffle(arr) {
let len = arr.length;
while (len) {
let i = (Math.random() * len--) >> 0;// 获得随机数
// 交换位置
let temp = arr[len];
arr[len] = arr[i];
arr[i] = temp;
}
return arr;
}
再结合 ES6 的解构赋值,使用洗牌算法就更方便了:
Array.prototype.shuffle = function() {
let m = this.length, i;
while (m) {
i = (Math.random() * m--) >> 0;
[this[m], this[i]] = [this[i], this[m]]
}
return this;
}
# 经典数组扁平化
# 【1】暴力toString (opens new window)
arr.toString().split(',').map((item) => parseInt(item))
嗯 Array.prototype.toString() (opens new window) 能这么用是我没想到的

再遍历下数组对数组元素挨个Number()一下 字符串->整数
# 【2】递归实现(妙啊!)
- 不使用API来打平多维数组
参考:红宝书
结合下面的过程看 很清晰~

本算法的递归调用边界和平常力扣(做二叉树/链表)遇到的不太相似(设置一个退出条件)
本算法中,只有前面的if else执行完了,才会弹出递归调用栈~
理解这一点 就很好想了!
另外,递归出口(弹栈时机)——
return xxx;把这个点想好,也是理解递归问题的关键!
【2】出递归调用栈时 0插入结果数组(return flattenedArray——[0])
然后的一维元素没有进入递归调用栈 1 2插入结果数组
【3】将函数flatten([3,[4,5]], [0,1,2]) 插入递归调用栈
【4】调用flatten([3,[4,5]], [0,1,2]) 时 3插入结果数组
【5】将函数flatten([4,5],[0,1,2,3]) 插入递归调用栈
【6】出递归调用栈时 4 5插入结果数组(return flattenedArray——[4,5])
最终flatten([3,[4,5]], [0,1,2])弹出递归调用栈(这块儿上面的图不太对哈!)(return flattenedArray——[0,1,2,3,4,5])
然后的一维元素没有进入递归调用栈 插入结果数组6
- 限定打平到第几层嵌套递归
参考 红宝书

# 【3】调API嘛 不丢人
- 调用ES2019的新API flat~~
arr.flat(Infinity)可以扁平化不管多深的多维数组~

- 还有一个没咋见过的flatMap()操作hhh

# 经典数组排序
知识点:V8中sort函数的实现机制
sort()方法用原地算法 (opens new window)对数组的元素进行排序,并返回数组。默认排序顺序是在将元素转换为字符串,然后比较它们的UTF-16代码单元值序列时构建的— MDN
关于
Array.prototype.sort(),ES 规范并没有指定具体的算法,在 V8 引擎中, 7.0 版本之前 ,数组长度小于10时,Array.prototype.sort()使用的是插入排序,否则用快速排序。在 V8 引擎 7.0 版本之后 就舍弃了快速排序,因为它不是稳定的排序算法,在最坏情况下,时间复杂度会降级到 O(n^2^)。
于是采用了一种混合排序的算法:TimSort 。
这种功能算法最初用于Python语言中,严格地说它不属于以上10种排序算法中的任何一种,属于一种混合排序算法:
在数据量小的子数组中使用插入排序,然后再使用归并排序将有序的子数组进行合并排序,时间复杂度为
O(nlogn)。作者:an_371e 链接:https://www.jianshu.com/p/a557e9006186 来源:简书
# Object类型相关知识,及常见api
# Object.prototype.toString()
- 判断引用数据类型的最佳方案!!!
- 面试很可能会考察这部分内容!

RefExp和Array的显式原型上都重写了toString这个方法 所以我们用的时候必须得重新调用Object原型链上的方法!!
# 对象的基本概念
来自蚂蚁成电校园行分享会
对象是非常重要的概念
我们把对象理解为:存放属性的容器
常用的内置对象:Math JSON Map Set Array
JSON是序列化传输数据的方式(是一个数据格式)
JSON.stringify()方法将一个 JavaScript 对象或值转换为 JSON 字符串console.log(JSON.stringify({ x: 5, y: 6 })); // expected output: "{"x":5,"y":6}" console.log(JSON.stringify([new Number(3), new String('false'), new Boolean(false)])); // expected output: "[3,"false",false]" console.log(JSON.stringify({ x: [10, undefined, function(){}, Symbol('')] })); // expected output: "{"x":[10,null,null,null]}" console.log(JSON.stringify(new Date(2006, 0, 2, 15, 4, 5))); // expected output: ""2006-01-02T15:04:05.000Z""
JSON.parse()方法用来解析JSON字符串,构造由字符串描述的JavaScript值或对象const json = '{"result":true, "count":42}'; const obj = JSON.parse(json); console.log(obj.count); // expected output: 42 console.log(obj.result); // expected output: true
宿主对象
- 浏览器宿主:Window、History、Location
- Node宿主:global等
# JavaScript toString() 方法
toString方法在Object的显示原型上,其他对象对toString方法进行了重写~

toString() 方法可把一个 Number 对象转换为一个字符串,并返回结果。
语法
NumberObject.toString(radix)// radix就是指进制数
# 比较有趣的一个点

小数居然算是
Number Object…?
答疑:看了下MDN Number.prototype.toString() (opens new window) 得知——
- (10) 是 numObj 10不是
- (0.6) 是 numObj 0.6也是numObj

var count = 10; console.log(count.toString()); // 输出 '10' console.log((17).toString()); // 输出 '17' console.log(17.toString()); // Uncaught SyntaxError: Invalid or unexpected token console.log((17.2).toString()); // 输出 '17.2' console.log(17.2.toString()); // 输出 '17.2' var x = 6; console.log(x.toString(2)); // 输出 '110' console.log((254).toString(16)); // 输出 'fe' console.log((-10).toString(2)); // 输出 '-1010' console.log((-0xff).toString(2)); // 输出 '-11111111'又来了个神奇的操作
10..toString();// 输出"10"听前辈说这个是因为 . 指代不明确
- 利用这个方法 配合
substr()方法 (opens new window) 可以实现随机验证码生成
Math.random().toString(36).substr(2, 10);// 以36进制将随机数转换为随机字符串,从得到的随机字符串的第二位开始拿10个字符~根本重复不了!
以36进制将随机数转换为随机字符串,从得到的随机字符串的第二位开始拿10个字符~根本重复不了!

# 函数、类相关
# 常见API
Function.prototype.call() - JavaScript | MDN (mozilla.org) (opens new window)
call() 方法使用一个指定的 this 值和单独给出的一个或多个参数来调用一个函数。
注意:该方法的语法和作用与 apply() (opens new window) 方法类似,只有一个区别,就是 call() 方法接受的是一个参数列表,而 apply() 方法接受的是一个包含多个参数的数组。
function Product(name, price) {
this.name = name;
this.price = price;
}
function Food(name, price) {
Product.call(this, name, price);
console.log(this);// Object { name: "cheese", price: 5 }
this.category = 'food';
}
console.log(new Food('cheese', 5).name);// "cheese"
# Function.prototype.apply() - JavaScript | MDN (opens new window)
apply() 方法调用一个具有给定this值的函数
const numbers = [5, 6, 2, 3, 7];
const max = Math.max.apply(null, numbers);
console.log(max);// expected output: 7
const min = Math.min.apply(null, numbers);
console.log(min);// expected output: 2
# Function.prototype.bind() - JavaScript | MDN (opens new window)
bind() 方法创建一个新的函数,在 bind() 被调用时,这个新函数的 this 被指定为 bind() 的第一个参数,而其余参数将作为新函数的参数,供调用时使用。
const module = {
x: 42,
getX: function() {
return this.x;
}
};
const unboundGetX = module.getX;
console.log(module.getX()); // 42
console.log(unboundGetX()); // The function gets invoked at the global scope expected output: undefined
// expected output: undefined
const boundGetX = unboundGetX.bind(module);
console.log(boundGetX());// expected output: 42
继承问题
通过原型链实现子类对父类的继承
Child.prototype = new Father();别忘了修正Child类显示原型的
constructor
Child.prototype.constructor = Child
# 继承模式
原型链继承 : 得到方法
- 通过
Child.prototype = new Parent()继承父函数 从而继承了属性与方法 - 缺点:通过Child构造的对象 的原型对象 的
constructor属性指向Parent!这不好!- 我们需要让子类型的原型的
constructor指向子类型 才对! - 这个问题可以通过
Child.prototype.constructor = Child;来修正constructor属性
- 我们需要让子类型的原型的
function Parent(){} Parent.prototype.test = function(){}; function Child(){} Child.prototype = new Parent(); // 子类型的原型指向父类型实例 Child.prototype.constructor = Child;// 修正constructor属性 var child = new Child(); //有test()- 通过
借用构造函数 : 得到属性
- 通过
Parent.call(this,name,age)继承(调用父类型构造函数) - 缺点:获得父类型的方法很麻烦!还得借助call方法一个个地弄
Parent.func.call(this,参数)
function Parent(xxx){this.xxx = xxx} Parent.prototype.test = function(){}; function Child(xxx,yyy){ Parent.call(this, xxx);//借用构造函数 this.Parent(xxx) // 相当于 this.Parent(xxx) } var child = new Child('a', 'b'); //child.xxx为'a', 但child没有test()- 通过
组合
function Parent(xxx){this.xxx = xxx} Parent.prototype.test = function(){}; function Child(xxx,yyy){ Parent.call(this, xxx);//借用构造函数 this.Parent(xxx) } Child.prototype = new Parent(); //得到test() var child = new Child(); //child.xxx为'a', 也有test()
# JS实现继承的最佳实践
使用 原型链结合构造函数
在父类型属性有很多条时 使用
Parent.call(this,父函数属性)让子类型继承
function Parent(attribute,other){
this.attribute = attribute;
this.other = other;
}
Parent.prototype.output = function(){
console.log("此方法位于Parent的显式原型中 Child构造函数继承了我 所以Child的实例对象可以顺着隐式原型连找到这个对象(在Object对象上)");
}
function Child(attribute, other){
Parent.call(this,attribute,other);// 继承父类型的属性
}
Child.prototype = new Parent();// 原型链继承!让子类型的显式原型指向父类型的实例!
Child.prototype.constructor = Child;// 出于严谨 这里修正constructor属性 要不然Child的显式原型的constructor就是Parent了 这就很奇怪!
var child = new Child('a', 'b');// ['a', 'b']
child.output();

上面的属性的输出有些问题
JS继承最佳实践完整版输出如下:

好吧上面的还是不全 有点小问题——
Child.prototype.constructor = Child;// 出于严谨 这里修正constructor属性 要不然Child的显式原型的constructor就是Parent了 这就很奇怪!
// 修正完 constructor指向Child构造函数
# this关键字
this会作为变量一直向上级词法作用域查找,直至找到为止
# coderwhy文章 (opens new window)
优先级从低到高
- 默认绑定
- 没有被绑定到某个对象上进行调用
- this指向window(严格模式下报错)
- 没有被绑定到某个对象上进行调用
- 隐式绑定
- 通过某个对象进行调用
- 显式绑定
- call apply bind
- new绑定
- new Function()
# 【神三元】原生JS灵魂之问(中),检验自己是否真的熟悉JavaScript? - 掘金 (juejin.cn) (opens new window)
其实JS中的this是一个非常简单的东西,只需要理解它的执行规则就OK。
在这里不想像其他博客一样展示太多的代码例子弄得天花乱坠, 反而不易理解。
call/apply/bind可以显式绑定, 这里就不说了。
主要这些场隐式绑定的场景讨论:
- 全局上下文
- 直接调用函数
- 对象.方法的形式调用
- DOM事件绑定(特殊)
- new构造函数绑定
- 箭头函数
# 1. 全局上下文
全局上下文默认this指向window, 严格模式下指向undefined。
# 2. 直接调用函数
比如:
let obj = {
a: function() {
console.log(this);
}
}
let func = obj.a;
func();
这种情况是直接调用。this相当于全局上下文的情况。
# 3. 对象.方法的形式调用
还是刚刚的例子,我如果这样写:
obj.a();
这就是对象.方法的情况,this指向这个对象
# 4. DOM事件绑定
onclick和addEventerListener中 this 默认指向绑定事件的元素。
IE比较奇异,使用attachEvent,里面的this默认指向window。
# 5. new+构造函数
此时构造函数中的this指向实例对象。
# 6. 箭头函数?
箭头函数没有this, 因此也不能绑定。里面的this会指向当前最近的非箭头函数的this,找不到就是window(严格模式是undefined)。比如:
let obj = {
a: function() {
let do = () => {
console.log(this);
}
do();
}
}
obj.a(); // 找到最近的非箭头函数a,a现在绑定着obj, 因此箭头函数中的this是obj
复制代码
优先级: new > call、apply、bind > 对象.方法 > 直接调用。
作者:神三元 链接:https://juejin.cn/post/6844903986479251464 来源:稀土掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
# 一道输出题引发的对箭头函数绑定的this的思考
var name = 'name';
var A = {
name: 'A',
sayHello: function() {
let s = () => console.log(this.name);
return s;
}
};
let sayHello = A.sayHello(); // A
sayHello();
var B = {
name: 'B'
};
sayHello.call(B); // A
函数中的this与定义时所处的上下文绑定,且不能被改变, 箭头函数this指向取决于它外层找到的离它最近的第一个非箭头函数的this。所以一直是A,且不能改变(apply,call都不行)——
因为箭头函数没有自己的this指针,通过
call()或apply()方法调用一个函数时,只能传递参数(不能绑定this---译者注),他们的第一个参数会被忽略。(这种现象对于bind方法同样成立---译者注)
# MDN文档学习 (opens new window)
箭头函数没有自己的this指针,探究其通过 call 或 apply 调用后的局限性
Function.prototype.call() (opens new window)
call()方法使用一个指定的this值和单独给出的一个或多个参数来调用一个函数。该方法的语法和作用与
apply()(opens new window) 方法类似,只有一个区别,就是call()方法接受的是一个参数列表,而apply()方法接受的是一个包含多个参数的数组。function.call(thisArg, arg1, arg2, ...)
- thisArg
可选的。在
function函数运行时使用的this值。请注意,
this可能不是该方法看到的实际值:如果这个函数处于非严格模式 (opens new window)下,则指定为null或undefined时会自动替换为指向全局对象,原始值会被包装。
- arg1, arg2, ...
指定的参数列表。
由于 箭头函数没有自己的this指针,通过 call() 或 apply() 方法调用一个函数时,只能传递参数(不能绑定this---译者注),他们的第一个参数会被忽略。(这种现象对于bind方法同样成立---译者注)
举个例子就知道了
var adder = {
base: 1,
add:function(a){
var f = value => value + this.base;
return f(a);// thisArg未指定则默认指向全局对象adder
},
addThruCall:function(a){
var b = {base: 666};
var f = value => value + this.base;// 如果这里是个普通函数,则进行call时,将给b这个对象调用f方法,base为666
return f.call(b, a);
}
}
console.log(adder.add(1));// 2(adder.base + 1)
console.log(adder.addThruCall(1));// 2(依然是adder.base(而不是b.) + 1)
# 阮大教程 偏基础,偏底层原理,例子很简单
this指向函数运行时所在的环境,那么为什么this关键字有这样的作用?函数的运行环境是如何决定的?看看阮一峰大大写得这篇文章,你会有新的感悟!(真的让我对内存、对象等知识都有了新的认识!)
【阮大】JavaScript 的 this 原理 (opens new window)
粘一下this的定义:
由于函数可以在不同的运行环境执行,所以需要有一种机制,能够在函数体内部获得当前的运行环境(context)。所以,
this就出现了,它的设计目的就是在函数体内部,指代函数当前的运行环境。
# 这篇文章中例子很多,做完以后面试题应该是不怕了!
this到底指向哪里? (opens new window)
在JavaScript中
this的指向总是让人很困惑,它到底指的啥?。this在不同的执行环境,不同的用法下会有所不同,以下分几种情况,讨论this的指向。
总结:
- 对于函数中的
this,通过查看()左边所属的对象去确定,真的很好用。- 实质上,
this是在创建函数的执行环境时,在创建阶段确定的,因此,弄透执行环境,去思考执行环境创建阶段的this的指向,this的指向就不会弄错了雀氏!在使用new关键字创建对象时,其中一步就是“构造函数内部的this被赋值为这个创建好的新对象(即this指向新对象)”(参考红宝书)

# 深入理解JS函数中this指针的指向 (opens new window)
又是一篇前辈的文章,例子和情景都很全面!
小结:
函数在执行时,会在函数体内部自动生成一个this指针。谁直接调用产生这个this指针的函数,this就指向谁。
由于js是采用的静态作用域(也叫词法作用域),这就意味着函数的执行依赖于函数定义的时候所产生(而不是函数调用的时候产生)的变量作用域。
在全局作用域中“定义”一个函数的时候,只会创建包含全局作用域的作用域链。只有“执行”该函数的时候,才会复制创建时的作用域,并将当前函数的局部作用域放在作用域链的顶端。
去取变量值的时候,首先看本函数里有没有该值,如果没有再到函数定义的外部去找
# [JavaScript中arguments0表示的是什么?](https://www.zhihu.com/question/21466212)
var length = 10;
function fn(){
alert(this.length)
}
var obj = {
length: 5,
method: function(fn) {
arguments[0]()
}
}
obj.method(fn)// 输出1
obj.method(fn,1,1)// 输出3
为啥这里的this指向了arguments呢?因为在Javascript里,数组只不过使用数字做属性名的方法,也就是说:arguments[0]()的意思,和arguments.0()的意思差不多(当然这么写是不允许的),你更可以这么理解:
arguments = {
0: fn, //也就是 functon() {alert(this.length)}
1: 第二个参数, //没有
2: 第三个参数, //没有
...,
length: 1 //只有一个参数
}
- 变式 输出10
var length = 10;
function fn(){
alert(this.length)
}
var obj = {
length: 5,
method: function(fn) {
fn()
}
}
obj.method(fn)// 输出10——全局的length
- 变式 输出5
var length = 10;
function fn(){
console.log(this.length)
}
var obj = {
length: 5,
method: fn
}
obj.method()// 输出5 fn中的this绑定的是obj
var length = 10;
function fn(){
console.log(this.length)
}
var obj = {
length: 5,
method: function(fn) {
fn.call(obj)
// fn.call(this)
}
}
obj.method(fn)
# 箭头函数与this~
# 1.箭头函数与普通函数的区别?
1.箭头函数的参数只有一个时,可以省略小括号(但是!这里最好是带上括号 (opens new window)哦!),函数里面的执行语句只有一条时,可以省略花括号(但是!如果回调函数没有return 则最好加上大括号 (opens new window) ——减少副作用) 2.箭头函数本身没有this,它会继承作用域链上一层的this 3.箭头函数不能使用call, bind, apply来改变this指向
- 写法不一样
function foo() {
console.log('1')
}
const foo = () => {
console.log('1')
}
- 普通函数存在变量提升的现象 箭头函数只会被提升变量
// 普通函数
foo()
function foo() {
console.log('1')
}
// 箭头函数
foo() //报错 foo is not a function
let foo = () => {
console.log('1')
}
- 箭头函数不能作为构造函数使用
- 函数中没有prototype属性
- this也不是自己的this
- 这怎么new呐~
let Person = (name) => {
this.name = name
}
let xiao_ming = new Person('小明')
console.log(xiao_ming.name) //undefined
- 两者this的指向不同
普通函数的this指向的是谁调用该函数就指向谁
箭头函数的this指向的是定义时上下文的this值(哪儿定义的 this就绑的哪儿),如果没有上下文环境对象,那么就指向最外层对象window。
- 箭头函数的arguments指向它的父级函数所在作用域的arguments
function foo() {
console.log(arguments)
let foo1 = () => {
console.log(arguments)
}
foo1()
}
foo('test')
//[Arguments] { '0': 'test' }
//[Arguments] { '0': 'test' }
- 箭头函数没有new.target
先说明下new.target是干嘛的,这家伙是用来检测函数是否被当做构造函数使用,他会返回一个指向构造函数的引用。
因为箭头函数不能当做构造函数使用,自然是没有new.target的。
# this指向哪里?
其实this指向的问题情况并不多,但是它在不同的执行条件下可能会绑定(指向)不同的对象,如果想要再深入了解,可以看一下coderwhy的这篇文章 (opens new window)
- 普通函数中:this->window
- 定时器中:this->window
- 构造函数中:this->当前实例化的对象
- 事件处理函数中:this->事件触发对象
- 在 js 中一般理解就是谁调用这个 this 就指向谁
# 原型、原型链
# prototype __proto__ constructor的作用
- prototype
用来挂载方法~
__proto__- constructor
# 获取对象原型的方法
每一个构造函数的内部都有一个 prototype 属性,它的属性值是一个对象,这个对象包含了可以由该构造函数的所有实例共享的属性和方法。
当使用构造函数新建一个对象后,在这个对象的内部将包含一个指针,这个指针指向构造函数的 prototype 属性对应的值,在 ES5 中这个指针被称为对象的原型。
浏览器中实现了 __proto__ 属性来访问这个属性,但是最好不要使用这个属性,因为它不是规范中规定的。
ES5 中新增了一个 Object.getPrototypeOf() 方法,可以通过这个方法来获取对象的原型。
# 判断属性是否属于原型链的属性
使用hasOwnProperty() (opens new window)方法来判断属性是否属于原型链的属性:
hasOwnProperty()方法会返回一个布尔值,指示对象自身属性中是否具有指定的属性(也就是,是否有指定的键)。
function iterate(obj){
var res=[];
for(var key in obj){
if(obj.hasOwnProperty(key))
res.push(key+': '+obj[key]);
}
return res;
}
这不比判断原型链啥的省脑子hh(当然方法还是得顺着原型链找咯)
# Object.prototype.isPrototypeOf() (opens new window)
isPrototypeOf() 方法用于测试一个对象是否存在于另一个对象的原型链上。
isPrototypeOf()与instanceof(opens new window) 运算符不同。在表达式 "object instanceof AFunction"中,object的原型链是针对AFunction.prototype进行检查的,而不是针对AFunction本身。
本示例展示了 Baz.prototype, Bar.prototype, Foo.prototype 和 Object.prototype 在 baz 对象的原型链上:
function Foo() {}
function Bar() {}
function Baz() {}
Bar.prototype = Object.create(Foo.prototype);
Baz.prototype = Object.create(Bar.prototype);
var baz = new Baz();
console.log(Baz.prototype.isPrototypeOf(baz)); // true
console.log(Bar.prototype.isPrototypeOf(baz)); // true
console.log(Foo.prototype.isPrototypeOf(baz)); // true
console.log(Object.prototype.isPrototypeOf(baz)); // true
# 闭包、作用域相关(面试手写题常客)
# 对闭包Scope (opens new window)的理解
另外之前写过一篇入门级的文章 从函数提升谈到闭包~ (opens new window)
闭包是指有权访问另一个函数作用域中变量的函数,创建闭包的最常见的方式就是在一个函数内创建另一个函数,创建的函数可以访问到当前函数的局部变量。
- 比如,函数 A 内部有一个函数 B,函数 B 可以访问到函数 A 中的变量,那么函数 B 就是闭包。
function A() {
let a = 1
window.B = function () {
console.log(a)
}
}
A()
B() // 1
在 JS 中,闭包存在的意义就是让我们可以间接访问函数内部的变量。

- 经典面试题:循环中使用闭包解决 var 定义函数的问题
for (var i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i)
}, i * 1000)
}
首先因为 setTimeout 是个异步函数,所以会先把循环全部执行完毕,这时候 i 就是 6 了,所以会输出一堆 6。解决办法有三种:
- 第一种是使用闭包的方式
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout(function timer() {
console.log(j)
}, j * 1000)
})(i)
}
在上述代码中,首先使用了立即执行函数将 i 传入函数内部,这个时候值就被固定在了参数 j 上面不会改变,当下次执行 timer 这个闭包的时候,就可以使用外部函数的变量 j,从而达到目的。
- 第二种就是使用
setTimeout的第三个参数,这个参数会被当成timer函数的参数传入。
for (var i = 1; i <= 5; i++) {
setTimeout(
function timer(j) {
console.log(j)
},
i * 1000,
i
)
}
- 第三种就是使用
let定义i了来解决问题了,这个也是最为推荐的方式
for (let i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i)
}, i * 1000)
}
# 闭包何时被销毁?-垃圾回收机制
研究闭包的时候很好奇,啥时候闭包被销毁?
最终结论-如果没有特殊的垃圾回收算法(暂时没有搜索到有这种算法)会造成闭包常驻!除非手动设置为null 否则就会造成内存泄露!
查阅官方文档——
高级语言解释器嵌入了“垃圾回收器”,它的主要工作是跟踪内存的分配和使用,以便当分配的内存不再使用时,自动释放它。这只能是一个近似的过程,因为要知道是否仍然需要某块内存是无法判定的 (opens new window)(无法通过某种算法解决)。
“垃圾回收实现只能有限制的解决一般问题,垃圾回收算法主要依赖于引用的概念。”
举个例子(来自官方文档,我加了一些注释)
var o = {
a: {
b:2
}
};
// 下面提到的"这个对象" 即为 {a:{b:2}}
// 两个对象被创建,一个作为另一个的属性被引用,另一个被分配给变量o
// 很显然,没有一个可以被垃圾收集
var o2 = o; // o2变量是第二个对“这个对象”的引用
o = 1; // 现在,“这个对象”只有一个o2变量的引用了,“这个对象”的原始引用o(原来是对象{a:{b:2}},现在是个数值型,直接扔栈里就可以了!)已经没有
var oa = o2.a; // 引用“这个对象”的a属性
// 现在,“这个对象”有两个引用了,一个是o2,一个是oa
o2 = "yo"; // 虽然最初的对象现在已经是零引用了,可以被垃圾回收了
// 但是它的属性a的对象还在被oa引用,所以还不能回收
oa = null; // a属性的那个对象现在也是零引用了
// 它可以被垃圾回收了
# 对作用域、作用域链的理解
# 1)全局作用域和函数作用域
(1)全局作用域
- 最外层函数和最外层函数外面定义的变量拥有全局作用域
- 所有未定义直接赋值的变量自动声明为全局作用域
- 所有window对象的属性拥有全局作用域
- 全局作用域有很大的弊端,过多的全局作用域变量会污染全局命名空间,容易引起命名冲突。
(2)函数作用域
- 函数作用域声明在函数内部的变量,一般只有固定的代码片段可以访问到
- 作用域是分层的,内层作用域可以访问外层作用域,反之不行
# 2)块级作用域
- 使用ES6中新增的let和const指令可以声明块级作用域,块级作用域可以在函数中创建也可以在一个代码块中创建(由
{ }包裹的代码片段) - let和const声明的变量不会有变量提升,也不可以重复声明
- 在循环中比较适合绑定块级作用域,这样就可以把声明的计数器变量限制在循环内部。
# 3)作用域链:
在当前作用域中查找所需变量,但是该作用域没有这个变量,那这个变量就是自由变量。如果在自己作用域找不到该变量就去父级作用域查找,依次向上级作用域查找,直到访问到window对象就被终止,这一层层的关系就是作用域链。
作用域链的作用是保证对执行环境有权访问的所有变量和函数的有序访问,通过作用域链,可以访问到外层环境的变量和函数。
作用域链的本质上是一个指向变量对象的指针列表。变量对象是一个包含了执行环境中所有变量和函数的对象。作用域链的前端始终都是当前执行上下文的变量对象。全局执行上下文的变量对象(也就是全局对象)始终是作用域链的最后一个对象。
当查找一个变量时,如果当前执行环境中没有找到,可以沿着作用域链向后查找。
# 对执行上下文的理解
# 1. 执行上下文类型
(1)全局执行上下文
任何不在函数内部的都是全局执行上下文,它首先会创建一个全局的window对象,并且设置this的值等于这个全局对象,一个程序中只有一个全局执行上下文。
(2)函数执行上下文
当一个函数被调用时,就会为该函数创建一个新的执行上下文,函数的上下文可以有任意多个。
# 2. 执行上下文栈
- JavaScript引擎使用执行上下文栈来管理执行上下文
- 当JavaScript执行代码时,首先遇到全局代码,会【1】创建一个全局执行上下文并且压入执行栈中,每当遇到一个函数调用,就会【2】为该函数创建一个新的执行上下文并压入栈顶,引擎会执行位于执行上下文栈顶的函数,当函数执行完成之后,【3】执行上下文从栈中弹出,【4】继续执行下一个上下文。当所有的代码都执行完毕之后,从【5】栈中弹出全局执行上下文。
let a = 'Hello World!';
function first() {
console.log('Inside first function');// 1
second();// 2
console.log('Again inside first function');// 3
}
function second() {
console.log('Inside second function');
}
first();
//执行顺序
//先执行second(),再执行first()-这里存疑 虽说second函数确实是在栈顶吧!
# 3. 创建执行上下文
创建执行上下文有两个阶段:创建阶段和执行阶段
1)创建阶段
(1)this绑定
- 在全局执行上下文中,this指向全局对象(window对象)
- 在函数执行上下文中,this指向取决于函数如何调用。如果它被一个引用对象调用,那么 this 会被设置成那个对象(
let func = new Fn()这里构造函数中的this就被设置为这个实例对象了!),否则 this 的值被设置为全局对象或者 undefined
下面这俩没听说过的说
(2)创建词法环境组件
- 词法环境是一种有标识符——变量映射的数据结构,标识符是指变量/函数名,变量是对实际对象或原始数据的引用。
- 词法环境的内部有两个组件:加粗样式:环境记录器:用来储存变量个函数声明的实际位置外部环境的引用:可以访问父级作用域
(3)创建变量环境组件
- 变量环境也是一个词法环境,其环境记录器持有变量声明语句在执行上下文中创建的绑定关系。
2)执行阶段
此阶段会完成对变量的分配,最后执行完代码。
简单来说执行上下文就是指:
在执行一点JS代码之前,需要先解析代码。解析的时候会【1】先创建一个全局执行上下文环境,先【2】把代码中即将执行的变量、函数声明都拿出来,【3】变量先赋值为undefined,【4】函数先声明好可使用。这一步执行完了,才【5】开始正式的执行程序。
在一个函数执行之前,也会创建一个函数执行上下文环境,跟全局执行上下文类似,不过函数执行上下文会多出this、arguments和函数的参数。
- 全局上下文:变量定义,函数声明
- 函数上下文:变量定义,函数声明,
this,arguments
# 静态作用域的两道基础题
# 面试题考察静态性-面试题1
var x = 10;
function fn(){
console.log(x);// 10
}
function show(f){
var x = 20;
f();
}
show(fn);// 打印10
记住一句话——
在其他函数中被调用不影响x在打印语句中的值(x在一开始定义的时候就确定了 打印的x是全局中的(毕竟是在人家全局那里调用的函数show嘛~))
21/10/17 更新 感觉可以用执行上下文来解释?毕竟涉及到了函数调用,很动态~

21/10/31更新
又见到了一次这道题
感觉上面的说法可能有一定道理,但是作用域的“静态性”才是最权威解释——在调用一个函数时,要找到它最开始被创建时的位置,进行寻值
# 作用域链面试题~沿着作用域链找某个变量-面试题2
var fn = function () {
console.log(fn)//function(){console.log(fn)}
var fn2 = function(){
console.log("找不到我吧~");
}
}
fn()
var obj = {
fn2: function () {
console.log(fn2)// 报错 fn2 is not defined
console.log(this.fn2)//function(){...}
}
}
obj.fn2()
首先 第二行的打印是 fn对象(人家顺着作用域链就能轻松找到位于全局作用域中的fn咯~)
第十一行 报错 来看看fn2的心路历程
- 先在fn2构造函数的函数作用域中找 没有定义过fn2!
- 再去全局作用域里找 全局变量也没它这号变量!
- 再去同级的函数作用域里找找行么?
- 不行!😂
第十二行 打印fn2对象 加上this 表示obj对象 obj对象拥有这个fn2函数啊 没问题~
# 异步编程
# promise异步输出问题-依次输出1 2 3 end
const promise1 = () => Promise.resolve(1);
const promise2 = () =>
new Promise((resolve) => {
setTimeout(() => {
resolve(2);
}, 1000)
});
const promise3 = () =>
new Promise((resolve) => {
setTimeout(() => {
resolve(3);
}, 1000)
})
const promiseList = [promise1, promise2, promise3];
// 法1 用async await
// const promiseChain = async(promiseList) => {
// for (let promise of promiseList) {
// const res = await promise();
// console.log(res);
// }
// }
// 使用立即执行函数(如果不让改25行这里的代码的话)
// function promiseChain(promiseList) {
// return (async () => {
// for (let promise of promiseList) {
// // console.log(promise);
// const res = await promise();
// console.log(res);
// }
// })();
// }
// 法二 使用reduce 创造回调链
const promiseChain = () => {
const res = promiseList.reduce((prevPromise, curPromise, index) => {
return prevPromise.then((res) => {
index && console.log(res);
return curPromise();
});
}, Promise.resolve());
// 这两行一个意思 45行的方法更加秀~
// return Promise.resolve(res).then(console.log)
return Promise.resolve(res).then((res) => console.log(res));
};
// 整体流程如下——
// return promise1()
// .then((res) => {
// console.log(res);
// return promise2();
// })
// .then((res) => {
// console.log(res);
// return promise3();
// })
// .then((res) => {
// console.log(res);
// });
promiseChain(promiseList).then(() => console.log('执行完毕'));
# Promise的使用方法&理解
Promise本身是同步的立即执行函数, 当在executor中执行resolve或者reject的时候, 此时是异步操作, 会先执行then/catch等,当主栈完成后,才会去调用resolve/reject中存放的方法执行,打印的时候,是打印的返回结果,一个Promise实例。
console.log('script start')
let promise1 = new Promise(function (resolve) {
console.log('promise1')
resolve()
console.log('promise1 end')
}).then(function () {
console.log('promise2')
})
setTimeout(function(){
console.log('settimeout')
})
console.log('script end')
// 输出顺序: script start->promise1->promise1 end->script end->promise2->settimeout
当JS主线程执行到Promise对象时:
- promise1.then() 的回调就是一个 task
- promise1 是 resolved或rejected: 那这个 task 就会放入当前事件循环回合的 microtask queue(微任务队列)
- promise1 是 pending: 这个 task 就会放入 事件循环的未来的某个(可能下一个)回合的 microtask queue 中
- setTimeout 的回调也是个 task ,它会被放入 macrotask queue(宏任务队列) 即使是 0ms 的情况
# Promise调用机制总结

# async、await相关
# 理解 JavaScript 的 async/await (opens new window)
简单来说
如果await等到的不是一个 Promise 对象,那 await 表达式的运算结果就是它等到的东西。 如果await等到的是一个 Promise 对象,await 就忙起来了,它会阻塞后面的代码,等着 Promise 对象 resolve,然后得到 resolve 的值,作为 await 表达式的运算结果。
举例,用 setTimeout 模拟耗时的异步操作,先来看看不用 async/await 会怎么写
function takeLongTime() {
return new Promise(resolve => {
setTimeout(() => resolve("long_time_value"), 1000);
});
}
takeLongTime().then(v => {
console.log("got", v);
});
如果改用 async/await 呢,会是这样
function takeLongTime() {
return new Promise(resolve => {
setTimeout(() => resolve("long_time_value"), 1000);
});
}
async function test() {
const v = await takeLongTime();
console.log(v);
// console.log("async end");
}
/console.log("script end");
test();
单一的 Promise 链并不能发现 async/await 的优势,但是,如果需要处理由多个 Promise 组成的 then 链的时候,优势就能体现出来了(很有意思,Promise 通过 then 链来解决多层回调的问题,现在又用 async/await 来进一步优化它)。
假设一个业务,分多个步骤完成,每个步骤都是异步的,而且依赖于上一个步骤的结果。我们仍然用 setTimeout 来模拟异步操作:
/**
* 传入参数 n,表示这个函数执行的时间(毫秒)
* 执行的结果是 n + 200,这个值将用于下一步骤
*/
function takeLongTime(n) {
return new Promise(resolve => {
setTimeout(() => resolve(n + 200), n);
});
}
function step1(n) {
console.log(`step1 with ${n}`);
return takeLongTime(n);
}
function step2(n) {
console.log(`step2 with ${n}`);
return takeLongTime(n);
}
function step3(n) {
console.log(`step3 with ${n}`);
return takeLongTime(n);
}
现在用 Promise 方式来实现这三个步骤的处理
function doIt() {
console.time("doIt");
const time1 = 300;
step1(time1)
.then(time2 => step2(time2))
.then(time3 => step3(time3))
.then(result => {
console.log(`result is ${result}`);
console.timeEnd("doIt");
});
}
doIt();
// c:\var\test>node --harmony_async_await .
// step1 with 300
// step2 with 500
// step3 with 700
// result is 900
// doIt: 1507.251ms
输出结果 result 是 step3() 的参数 700 + 200 = 900。doIt() 顺序执行了三个步骤,一共用了 300 + 500 + 700 = 1500 毫秒,和 console.time()/console.timeEnd() 计算的结果一致。
如果用 async/await 来实现呢,会是这样
async function doIt() {
console.time("doIt");
const time1 = 300;
const time2 = await step1(time1);
const time3 = await step2(time2);
const result = await step3(time3);
console.log(`result is ${result}`);
console.timeEnd("doIt");
}
doIt();
结果和之前的 Promise 实现是一样的,但是这个代码看起来是不是清晰得多,==几乎跟同步代码一样==
# async 函数的含义和用法 (opens new window)

# xhr、fetch相关(AJAX)
# 浏览器中的JavaScript
DOM核心API部分来自 蚂蚁前端校园行,虽然现在的开发都是脱离DOM,基于虚拟DOM进行开发,但是基础知识还是要了解的!毕竟VDOM也是要转换为DOM的~
# DOM核心API-1
获取DOM中的节点
document.getElementById('id')(opens new window)document.querySelector('selecotrs')(opens new window)- id、class
querySelector('#root')
- 更高级一些——标签名、CSS属性值
querySelector(input[name = 'login'])name属性为login的input元素
- id、class
# DOM核心API-2
动态地创建节点并插入到DOM中
element.style.xxx(opens new window)(MDN里甚至没有中文ORZ)- 设置获取元素的属性
document.createElement(要创建的标签名称/类名)(opens new window)node.appendChild(子节点)(opens new window)- 将子节点追加给父节点
Element.innerHTML(opens new window)
# DOM核心API-3
获取/设置元素的样式
element.getAttribute(name)(opens new window)element.setAttribute('属性名称', '属性的值/新值')(opens new window)
# DOM核心API-4
监听事件
# 事件
- 注册事件方法1
- 内容HTML和交互JS绑定在一起了,这样不好~(比较古老的写法)
<button id='btn'>onclick = "eventLog('onclick')"</button>
<script>
function eventLog(type){
console.log('触发的事件是:' + type)
}
</script>
- 注册事件的方法2
- 不用给标签加事件,直接用JS获取标签对应的元素然后使用
addEventListener(这个用得真的超级多!)
- 不用给标签加事件,直接用JS获取标签对应的元素然后使用
function eventLog(type){
console.log('触发的事件是:' + type)
}
const btn = document.querySelector('#btn');
btn.addEventListener('click', function(){
eventLog('onclick');
})
常见事件
- 鼠标点击事件
onclick = "回调函数"- 鼠标移入移出事件
onmouseover = "回调函数" onmouseout = "回调函数"- 文本改变事件
onchange = "回调函数";// 经常用onchange来监听输入框中的改变- 键盘输入事件
oninput = "回调函数";// 用这个监听全局的键盘键入- 输入框(光标)focus(聚焦)事件
onfocus = "回调函数"- 输入框(光标)blur失焦事件
onblur = "回调函数"虽然我们现在侦听事件一般用
addEventListener(‘xxx’, 回调函数)吧~(不包括框架!)但是原生的JS操作DOM还是要理解咧!- 因为追溯根源,框架就是帮助我们操作了DOM文档对象模型,后期性能优化的了解上这个必不可少!
# BOM相关
浏览器对象模型(Browser Object Model)的核心是 window 对象。是每个浏览器⼚商在浏览器上提供的,提供与浏览器交互的⽅法和接⼝(⽐如,跳转⻚⾯,获取窗⼝⼤⼩,获 取历史记录,获取当前页面URL,获取⽂档节点等) ⼤部分我们常⽤的接⼝都是相同的调⽤⽅式,但是浏览器他们底层实现的⽅式会不同。
# DOM注册事件的三种方法
- method01 页面元素(标签)提供的事件属性
<button onclick="myClick()" id="btn">xx</button>
- method02 使用DOM对象的事件属性
var btn = document.getElementById("btn");
// 给指定元素添加事件监听器
btn.onclick = myClick;
function myClick(){
xxx
}
- method03 事件监听器
var btn = document.getElementById("btn");
// 给指定元素添加事件监听器
btn.addEventListener('click', function () {
xxx
})
# 事件的冒泡与捕获
可以通过addEventListener()的第三个参数来确定捕获还是冒泡,第一个参数是要绑定的事件,第二个参数是回调函数,第三个参数默认是false,代表事件冒泡阶段调用事件处理函数,如果设置成true,则在事件捕获阶段调用处理函数。
冒泡:
还可以点JS30中第25个demo (opens new window)
微软提出了事件冒泡的事件流,事件会从最内层的元素开始发生,一直向上层传播,直到document对象。p元素上发生click事件的顺序应该是p -> body -> html -> document
捕获:
网景提出了事件捕获的事件流,事件捕获相反,事件会从最外层开始发生,直到最具体的元素。p元素上发生click事件的顺序应该是document -> html -> body -> div -> p
W3C制定了统一的标准,先捕获再冒泡。
# 更极端的情况
牢记:先捕获再冒泡
在浏览器中,如果父子元素都设置了捕获和冒泡的输出,当点击子元素时:
- 先捕获父元素
- 子元素输出先注册的事件
- 捕获先注册->输出捕获
- 冒泡先注册->输出冒泡
- 再输出父元素的冒泡事件
# 事件冒泡与阻止事件冒泡(与捕获)
使用
event.stopPropagation();// 阻止冒泡
# 阻止点击事件
event.defaultPrevented();// 阻止点击事件
event.cancelable();// 这样也可以?!
图如果看不了的话 直接访问图片链接也ok
https://gitee.com/su-fangzhou/blog-image/raw/master/202111150020231.png

# 正则表达式
# ES6、ES7、ES2020新增内容
# ?. ??
可选链操作符(
?.)- 可选链操作符(
?.)允许读取位于连接对象链深处的属性的值,而不必明确验证链中的每个引用是否有效。?.操作符的功能类似于.链式操作符,不同之处在于,在引用为空(nullish (opens new window) ) (null(opens new window) 或者undefined(opens new window)) 的情况下不会引起错误,该表达式短路返回值
- 可选链操作符(
空值合并操作符(
??)只有当左侧为null和undefined时,才会返回右侧的数
空值合并操作符(
??)是一个逻辑操作符,当左侧的操作数为null(opens new window) 或者undefined(opens new window) 时,返回其右侧操作数,否则返回左侧操作数。与逻辑或操作符(
||) (opens new window)不同,逻辑或操作符会在左侧操作数为假值 (opens new window)时返回右侧操作数。也就是说,如果使用||来为某些变量设置默认值,可能会遇到意料之外的行为。比如为假值(例如,''或0)时。见下面的例子。
# [Babel - ES6语法转换器](https://babeljs.io/repl#?browsers=defaults%2C not ie 11%2C not ie_mob 11&build=&builtIns=false&corejs=3.6&spec=false&loose=false&code_lz=DYUwLgBAhgTjEF4IG0BMAaAzOgLAXQG4AoWGAOhhABMBXAYxAApGo670I6aYBKRAPmhsIAaiRdeRIA&debug=false&forceAllTransforms=true&shippedProposals=false&circleciRepo=&evaluate=false&fileSize=false&timeTravel=false&sourceType=module&lineWrap=true&presets=env%2Creact%2Cstage-2&prettier=false&targets=&version=7.16.12&externalPlugins=&assumptions={})
# Map数据结构
# 初始化map
// 熟悉的《有效的括号》 hhh
const map = new Map([
["(", ")"],
["[", "]"],
["{", "}"]
])
键值对不多可以用map.set(key, value)
# 题目中 map的键的类型是字符型,所以可以用startsWith(xxx)方法来判断其前缀是否为xxx
碰到一道力扣 677. 键值映射 (opens new window),用到了字符串的这个API,很有趣也很实用!
var MapSum = function() {
this.map = new Map();
};
MapSum.prototype.insert = function(key, val) {
this.map.set(key, val);
};
MapSum.prototype.sum = function(prefix) {
let res = 0;
for (const s of this.map.keys()) {
console.log(typeof(s));// string
if (s.startsWith(prefix)) {
// 如果s开头是prefix,返回true
res += this.map.get(s);
}
}
return res;
};
# 30分钟掌握ES6/ES2015核心内容(上) (opens new window)
好文一篇 推荐~
# JS坑点
一些 JS的坑…
# 连续赋值问题
@淦!五行代码,难倒几十个前端群的小伙伴 (opens new window)
@javascript面试题,关于连续赋值let a = {n: 1}; let b = a; a.x = a = {n: 2}; 的坑 (opens new window)
需要结合JS引擎对堆内存和栈内存的管理来理解
这个经典面试题如下:
var a = {n: 1};
var b = a;
a.x = a = {n: 2}; // 这句的执行顺序是关键!!
console.log(a); // {n: 2}
console.log(b); // { n: 1, x: {n: 2} }
console.log(a === b.x); // true
【1】首先要明确基本概念
- 赋值运算符
=是从右向左运算的(依次将等号右侧的值赋值给等号左侧的)
- 例如 var a = 1 + 2; 先计算了等号右边1+2,将右边的结果3赋值给了a;
- 而我们都知道编程语言的运算顺序都是从左往右的,所以上题的执行顺序是——
- a.x = a
- a = { n: 2 }
【2】这个问题还可以从一个角度来考虑——连等为右结合性
上述问题可以看成—— a.x = ( a = {n:2} )

【3】最后一个关键
.运算符的优先级高于=,所以上述代码会先在a对象处创建x属性
【4】上述代码核心处三行代码对应的图(来自 juejin 速冻🐟)——
line 1 let a ={n:1}
line 2 let prevA=a
line3 a.x=(a={n:2})